Thank you to arXiv for use of its open access interoperability.
Note: the date of arXiv entries announced right after publication holidays might incorrectly show up as the date of the publication holiday itself. This is due to our ad hoc method of inferring announcement dates, which are not returned by the arXiv API.
In this work, we study the worst-case to average-case hardness of the Learning with Errors problem (LWE) under an alternative measure of hardness - the maximum success probability achievable by a probabilistic polynomial-time (PPT) algorithm. Previous works by Regev (STOC 2005), Peikert (STOC 2009), and Brakerski, Peikert, Langlois, Regev, Stehle (STOC 2013) give worst-case to average-case reductions from lattice problems to LWE, specifically from the approximate decision variant of the Shortest Vector Problem (GapSVP) and the Bounded Distance Decoding (BDD) problem. These reductions, however, are lossy in the sense that even the strongest assumption on the worst-case hardness of GapSVP or BDD implies only mild hardness of LWE. Our alternative perspective gives a much tighter reduction and strongly relates the hardness of LWE to that of BDD. In particular, we show that under a reasonable assumption about the success probability of solving BDD via a PPT algorithm, we obtain a nearly tight lower bound on the highest possible success probability for solving LWE via a PPT algorithm. Furthermore, we show a tight relationship between the best achievable success probability by any PPT algorithm for decision-LWE to that of search-LWE. Our results not only refine our understanding of the computational complexity of LWE, but also provide a useful framework for analyzing the practical security implications.
In this work, we study the worst-case to average-case hardness of the Learning with Errors problem (LWE) under an alternative measure of hardness - the maximum success probability achievable by a probabilistic polynomial-time (PPT) algorithm. Previous works by Regev (STOC 2005), Peikert (STOC 2009), and Brakerski, Peikert, Langlois, Regev, Stehle (STOC 2013) give worst-case to average-case reductions from lattice problems to LWE, specifically from the approximate decision variant of the Shortest Vector Problem (GapSVP) and the Bounded Distance Decoding (BDD) problem. These reductions, however, are lossy in the sense that even the strongest assumption on the worst-case hardness of GapSVP or BDD implies only mild hardness of LWE. Our alternative perspective gives a much tighter reduction and strongly relates the hardness of LWE to that of BDD. In particular, we show that under a reasonable assumption about the success probability of solving BDD via a PPT algorithm, we obtain a nearly tight lower bound on the highest possible success probability for solving LWE via a PPT algorithm. Furthermore, we show a tight relationship between the best achievable success probability by any PPT algorithm for decision-LWE to that of search-LWE. Our results not only refine our understanding of the computational complexity of LWE, but also provide a useful framework for analyzing the practical security implications.
We show that there is a constant $k$ such that Buss's intuitionistic theory
$\mathsf{IS}^1_2$ does not prove that SAT requires co-nondeterministic circuits
of size at least $n^k$. To our knowledge, this is the first unconditional
unprovability result in bounded arithmetic in the context of worst-case
fixed-polynomial size circuit lower bounds. We complement this result by
showing that the upper bound $\mathsf{NP} \subseteq \mathsf{coNSIZE}[n^k]$ is
unprovable in $\mathsf{IS}^1_2$.
We show that there is a constant $k$ such that Buss's intuitionistic theory
$\mathsf{IS}^1_2$ does not prove that SAT requires co-nondeterministic circuits
of size at least $n^k$. To our knowledge, this is the first unconditional
unprovability result in bounded arithmetic in the context of worst-case
fixed-polynomial size circuit lower bounds. We complement this result by
showing that the upper bound $\mathsf{NP} \subseteq \mathsf{coNSIZE}[n^k]$ is
unprovable in $\mathsf{IS}^1_2$.
The Mermin-Peres magic square is a celebrated example of a system of Boolean
linear equations that is not (classically) satisfiable but is satisfiable via
linear operators on a Hilbert space of dimension four. A natural question is
then, for what kind of problems such a phenomenon occurs? Atserias, Kolaitis,
and Severini answered this question for all Boolean Constraint Satisfaction
Problems (CSPs): For 2-SAT, Horn-SAT, and Dual Horn-SAT, classical
satisfiability and operator satisfiability is the same and thus there is no
gap; for all other Boolean CSPs, the two notions differ as there is a gap,
i.e., there are unsatisfiable instances that are satisfied via operators on a
finite-dimensional Hilbert space. We generalize their result to CSPs on
arbitrary finite domains: CSPs of so-called bounded-width have no
satisfiability gap, whereas all other CSPs have a satisfiability gap.
The Mermin-Peres magic square is a celebrated example of a system of Boolean
linear equations that is not (classically) satisfiable but is satisfiable via
linear operators on a Hilbert space of dimension four. A natural question is
then, for what kind of problems such a phenomenon occurs? Atserias, Kolaitis,
and Severini answered this question for all Boolean Constraint Satisfaction
Problems (CSPs): For 2-SAT, Horn-SAT, and Dual Horn-SAT, classical
satisfiability and operator satisfiability is the same and thus there is no
gap; for all other Boolean CSPs, the two notions differ as there is a gap,
i.e., there are unsatisfiable instances that are satisfied via operators on a
finite-dimensional Hilbert space. We generalize their result to CSPs on
arbitrary finite domains: CSPs of so-called bounded-width have no
satisfiability gap, whereas all other CSPs have a satisfiability gap.
In this paper, we study conditions for the existence of an embedding
$\widetilde{f} \colon P \to Q \times \mathbb{R}$ such that $f = \mathrm{pr}_Q
\circ \widetilde{f}$, where $f \colon P \to Q$ is a piecewise linear map
between polyhedra. Our focus is on non-degenerate maps between graphs, where
non-degeneracy means that the preimages of points are finite sets.
We introduce combinatorial techniques and establish necessary and sufficient
conditions for the general case. Using these results, we demonstrate that the
problem of the existence of a lifting reduces to testing the satisfiability of
a 3-CNF formula. Additionally, we construct a counterexample to a result by V.
Po\'{e}naru on lifting of smooth immersions to embeddings.
Furthermore, by establishing connections between the stated problem and the
approximability by embeddings, we deduce that, in the case of generic maps from
a tree to a segment, a weaker condition becomes sufficient for the existence of
a lifting.
In this paper, we study conditions for the existence of an embedding
$\widetilde{f} \colon P \to Q \times \mathbb{R}$ such that $f = \mathrm{pr}_Q
\circ \widetilde{f}$, where $f \colon P \to Q$ is a piecewise linear map
between polyhedra. Our focus is on non-degenerate maps between graphs, where
non-degeneracy means that the preimages of points are finite sets.
We introduce combinatorial techniques and establish necessary and sufficient
conditions for the general case. Using these results, we demonstrate that the
problem of the existence of a lifting reduces to testing the satisfiability of
a 3-CNF formula. Additionally, we construct a counterexample to a result by V.
Po\'{e}naru on lifting of smooth immersions to embeddings.
Furthermore, by establishing connections between the stated problem and the
approximability by embeddings, we deduce that, in the case of generic maps from
a tree to a segment, a weaker condition becomes sufficient for the existence of
a lifting.
Authors: Taige Zhao, Jianxin Li, Ningning Cui, Wei Luo
Community search over heterogeneous information networks has been applied to
wide domains, such as activity organization and team formation. From these
scenarios, the members of a group with the same treatment often have different
levels of activity and workloads, which causes unfairness in the treatment
between active members and inactive members (called individual unfairness).
However, existing works do not pay attention to individual fairness and do not
sufficiently consider the rich semantics of HINs (e.g., high-order structure),
which disables complex queries. To fill the gap, we formally define the issue
of individual fairest community search over HINs (denoted as IFCS), which aims
to find a set of vertices from the HIN that own the same type, close
relationships, and small difference of activity level and has been demonstrated
to be NP-hard. To do this, we first develop an exploration-based filter that
reduces the search space of the community effectively. Further, to avoid
repeating computation and prune unfair communities in advance, we propose a
message-based scheme and a lower bound-based scheme. At last, we conduct
extensive experiments on four real-world datasets to demonstrate the
effectiveness and efficiency of our proposed algorithms, which achieve at least
X3 times faster than the baseline solution.
Community search over heterogeneous information networks has been applied to
wide domains, such as activity organization and team formation. From these
scenarios, the members of a group with the same treatment often have different
levels of activity and workloads, which causes unfairness in the treatment
between active members and inactive members (called individual unfairness).
However, existing works do not pay attention to individual fairness and do not
sufficiently consider the rich semantics of HINs (e.g., high-order structure),
which disables complex queries. To fill the gap, we formally define the issue
of individual fairest community search over HINs (denoted as IFCS), which aims
to find a set of vertices from the HIN that own the same type, close
relationships, and small difference of activity level and has been demonstrated
to be NP-hard. To do this, we first develop an exploration-based filter that
reduces the search space of the community effectively. Further, to avoid
repeating computation and prune unfair communities in advance, we propose a
message-based scheme and a lower bound-based scheme. At last, we conduct
extensive experiments on four real-world datasets to demonstrate the
effectiveness and efficiency of our proposed algorithms, which achieve at least
X3 times faster than the baseline solution.
Networks play an ubiquitous role in computer science and real-world
applications, offering multiple kind of information that can be retrieved with
adequate methods. With the continuous growing in the amount of data available,
networks are becoming larger day by day. Consequently, the tasks that were
easily achievable on smaller networks, often becomes impractical on huge amount
of data, either due to the high computational cost or due to the impracticality
to visualise corresponding data. Using distinctive node features to group large
amount of connected data into a limited number of clusters, hence represented
by a representative per cluster, proves to be a valuable approach. The
resulting contracted graphs are more manageable in size and can reveal
previously hidden characteristics of the original networks. Furthermore, in
many real-world use cases, a definition of cluster is intrinsic with the data,
eventually obtained with the injection of some expert knowledge represent by a
categorical function. Clusters then results in set of connected vertices taking
the same values in a finite set C. In the recent literature, Lombardi and
Onofri proposed a novel, fast, and easily parallelisable approach under the
name of $\gamma$-contraction to contract a graph given a categorical function.
In this work, we formally define such approach by providing a rigorous
mathematical definition of the problem, which, to the best of our knowledge,
was missing in the existing literature. Specifically, we explore the variadic
nature of the contraction operation and use it to introduce the weaker version
of the colour contraction, under the name of $\beta$-contraction, that the
algorithmic solution exploits. We finally dive into the details of the
algorithm and we provide a full assesment on its convergence complexity relying
on two constructive proofs that deeply unveil its mode of operation.
Networks play an ubiquitous role in computer science and real-world
applications, offering multiple kind of information that can be retrieved with
adequate methods. With the continuous growing in the amount of data available,
networks are becoming larger day by day. Consequently, the tasks that were
easily achievable on smaller networks, often becomes impractical on huge amount
of data, either due to the high computational cost or due to the impracticality
to visualise corresponding data. Using distinctive node features to group large
amount of connected data into a limited number of clusters, hence represented
by a representative per cluster, proves to be a valuable approach. The
resulting contracted graphs are more manageable in size and can reveal
previously hidden characteristics of the original networks. Furthermore, in
many real-world use cases, a definition of cluster is intrinsic with the data,
eventually obtained with the injection of some expert knowledge represent by a
categorical function. Clusters then results in set of connected vertices taking
the same values in a finite set C. In the recent literature, Lombardi and
Onofri proposed a novel, fast, and easily parallelisable approach under the
name of $\gamma$-contraction to contract a graph given a categorical function.
In this work, we formally define such approach by providing a rigorous
mathematical definition of the problem, which, to the best of our knowledge,
was missing in the existing literature. Specifically, we explore the variadic
nature of the contraction operation and use it to introduce the weaker version
of the colour contraction, under the name of $\beta$-contraction, that the
algorithmic solution exploits. We finally dive into the details of the
algorithm and we provide a full assesment on its convergence complexity relying
on two constructive proofs that deeply unveil its mode of operation.
Authors: Bo Li, Lijun Li, Minming Li, Ruilong Zhang
We study a public event scheduling problem, where multiple public events are
scheduled to coordinate the availability of multiple agents. The availability
of each agent is determined by solving a separate flexible interval job
scheduling problem, where the jobs are required to be preemptively processed.
The agents want to attend as many events as possible, and their agreements are
considered to be the total length of time during which they can attend these
events. The goal is to find a schedule for events as well as the job schedule
for each agent such that the total agreement is maximized.
We first show that the problem is NP-hard, and then prove that a simple
greedy algorithm achieves $\frac{1}{2}$-approximation when the whole timeline
is polynomially bounded. Our method also implies a
$(1-\frac{1}{e})$-approximate algorithm for this case. Subsequently, for the
general timeline case, we present an algorithmic framework that extends a
$\frac{1}{\alpha}$-approximate algorithm for the one-event instance to the
general case that achieves $\frac{1}{\alpha+1}$-approximation. Finally, we give
a polynomial time algorithm that solves the one-event instance, and this
implies a $\frac{1}{2}$-approximate algorithm for the general case.
We study a public event scheduling problem, where multiple public events are
scheduled to coordinate the availability of multiple agents. The availability
of each agent is determined by solving a separate flexible interval job
scheduling problem, where the jobs are required to be preemptively processed.
The agents want to attend as many events as possible, and their agreements are
considered to be the total length of time during which they can attend these
events. The goal is to find a schedule for events as well as the job schedule
for each agent such that the total agreement is maximized.
We first show that the problem is NP-hard, and then prove that a simple
greedy algorithm achieves $\frac{1}{2}$-approximation when the whole timeline
is polynomially bounded. Our method also implies a
$(1-\frac{1}{e})$-approximate algorithm for this case. Subsequently, for the
general timeline case, we present an algorithmic framework that extends a
$\frac{1}{\alpha}$-approximate algorithm for the one-event instance to the
general case that achieves $\frac{1}{\alpha+1}$-approximation. Finally, we give
a polynomial time algorithm that solves the one-event instance, and this
implies a $\frac{1}{2}$-approximate algorithm for the general case.
Finding maximum cliques in large networks is a challenging combinatorial
problem with many real-world applications. We present a fast algorithm to
achieve the exact solution for the maximum clique problem in large sparse
networks based on efficient graph decomposition. A bunch of effective
techniques is being used to greatly prune the graph and a novel concept called
Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the
structures with the potential to form the maximum clique are retained in the
process of graph decomposition. Our algorithm first pre-prunes peripheral
nodes, subsequently, one or two small-scale CUBISs are constructed guided by
the core number and current maximum clique size. Bron-Kerbosch search is
performed on each CUBIS to find the maximum clique. Experiments on 50 empirical
networks with a scale of up to 20 million show the CUBIS scales are largely
independent of the original network scale. This enables an approximately linear
runtime, making our algorithm amenable for large networks. Our work provides a
new framework for effectively solving maximum clique problems on massive sparse
graphs, which not only makes the graph scale no longer the bottleneck but also
shows some light on solving other clique-related problems.
Finding maximum cliques in large networks is a challenging combinatorial
problem with many real-world applications. We present a fast algorithm to
achieve the exact solution for the maximum clique problem in large sparse
networks based on efficient graph decomposition. A bunch of effective
techniques is being used to greatly prune the graph and a novel concept called
Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the
structures with the potential to form the maximum clique are retained in the
process of graph decomposition. Our algorithm first pre-prunes peripheral
nodes, subsequently, one or two small-scale CUBISs are constructed guided by
the core number and current maximum clique size. Bron-Kerbosch search is
performed on each CUBIS to find the maximum clique. Experiments on 50 empirical
networks with a scale of up to 20 million show the CUBIS scales are largely
independent of the original network scale. This enables an approximately linear
runtime, making our algorithm amenable for large networks. Our work provides a
new framework for effectively solving maximum clique problems on massive sparse
graphs, which not only makes the graph scale no longer the bottleneck but also
shows some light on solving other clique-related problems.
Hairpin completion, derived from the hairpin formation observed in DNA
biochemistry, is an operation applied to strings, particularly useful in DNA
computing. Conceptually, a right hairpin completion operation transforms a
string $S$ into $S\cdot S'$ where $S'$ is the reverse complement of a prefix of
$S$. Similarly, a left hairpin completion operation transforms a string $S$
into $S'\cdot S$ where $S'$ is the reverse complement of a suffix of $S$. The
hairpin completion distance from $S$ to $T$ is the minimum number of hairpin
completion operations needed to transform $S$ into $T$. Recently Boneh et al.
showed an $O(n^2)$ time algorithm for finding the hairpin completion distance
between two strings of length at most $n$. In this paper we show that for any
$\varepsilon>0$ there is no $O(n^{2-\varepsilon})$-time algorithm for the
hairpin completion distance problem unless the Strong Exponential Time
Hypothesis (SETH) is false. Thus, under SETH, the time complexity of the
hairpin completion distance problem is quadratic, up to sub-polynomial factors.
Hairpin completion, derived from the hairpin formation observed in DNA
biochemistry, is an operation applied to strings, particularly useful in DNA
computing. Conceptually, a right hairpin completion operation transforms a
string $S$ into $S\cdot S'$ where $S'$ is the reverse complement of a prefix of
$S$. Similarly, a left hairpin completion operation transforms a string $S$
into $S'\cdot S$ where $S'$ is the reverse complement of a suffix of $S$. The
hairpin completion distance from $S$ to $T$ is the minimum number of hairpin
completion operations needed to transform $S$ into $T$. Recently Boneh et al.
showed an $O(n^2)$ time algorithm for finding the hairpin completion distance
between two strings of length at most $n$. In this paper we show that for any
$\varepsilon>0$ there is no $O(n^{2-\varepsilon})$-time algorithm for the
hairpin completion distance problem unless the Strong Exponential Time
Hypothesis (SETH) is false. Thus, under SETH, the time complexity of the
hairpin completion distance problem is quadratic, up to sub-polynomial factors.
In a pair of recent breakthroughs \cite{CHR,Li} it was shown that the classes $S_2^E, ZPE^{NP}$, and $\Sigma_2^E$ require exponential circuit complexity, giving the first unconditional improvements to a classical result of Kannan. These results were obtained by designing a surprising new algorithm for the total search problem Range Avoidance: given a circuit $C: \{0,1\}^n \to \{0,1\}^{n+1}$, find an $n+1$-bit string outside its range. Range Avoidance is a member of the class $TF\Sigma_2^P$ of total search problems in the second level of the polynomial hierarchy, analogous to its better-known counterpart $TFNP$ in the first level. $TF\Sigma_2^P$ was only recently introduced in \cite{KKMP} and its structure is not well understood. We investigate here the extent to which algorithms of the kind in \cite{CHR,Li} can be applied to other search problems in this class, and prove a variety of results both positive and negative.
On the positive side we show that Li's Range Avoidance algorithm \cite{Li} can be improved to give a reduction from Range Avoidance to a natural total search problem we call the Linear Ordering Principle or ``LOP'': given a circuit $\prec:\{0,1\}^n \times \{0,1\}^n \to \{0,1\}$ purportedly defining a total order on $\{0,1\}^n$, find either a witness that $\prec$ is not a total order or else a minimal element in the ordering. The problem LOP is quite interesting in its own right, as it defines a natural syntactic subclass ``$L_2^P$'' of $S_2^P$ which nonetheless maintains most of the interesting properties of $S_2^P$; in particular we show that $L_2^P$ contains $MA$ and that its exponential analogue ${L_2^E}$ requires $2^n/n$ size circuits. Both of these are consequences of our reduction from Range Avoidance to LOP.
On the negative side we prove that the algorithms developed in \cite{CHR,Li} cannot be extended to Strong Range Avoidance, a problem considered in the same paper which first introduced Range Avoidance \cite{KKMP}. In this problem we are given a circuit $C: \{0,1\}^n \setminus\{0^n\} \to \{0,1\}^n$, and once again seek a point outside its range. We give a separation in the decision tree (oracle) model showing that this problem cannot be solved in ${FP^{\Sigma_2^P}_{||}}$, which in particular rules out all of the new kinds of algorithms considered in \cite{CHR,Li}. This black box separation is derived from a novel depth 3 ${AC^0}$ circuit lower bound for a total search problem, which we believe is of independent interest from the perspective of circuit complexity: we show that unlike previous depth 3 lower bounds, ours cannot be proven by reduction from a decision problem, and thus requires new techniques specifically tailored to total search problems. Proving lower bounds of this kind was recently proposed by Vyas and Williams in the context of the original (Weak) Avoid problem.
In a pair of recent breakthroughs \cite{CHR,Li} it was shown that the classes $S_2^E, ZPE^{NP}$, and $\Sigma_2^E$ require exponential circuit complexity, giving the first unconditional improvements to a classical result of Kannan. These results were obtained by designing a surprising new algorithm for the total search problem Range Avoidance: given a circuit $C: \{0,1\}^n \to \{0,1\}^{n+1}$, find an $n+1$-bit string outside its range. Range Avoidance is a member of the class $TF\Sigma_2^P$ of total search problems in the second level of the polynomial hierarchy, analogous to its better-known counterpart $TFNP$ in the first level. $TF\Sigma_2^P$ was only recently introduced in \cite{KKMP} and its structure is not well understood. We investigate here the extent to which algorithms of the kind in \cite{CHR,Li} can be applied to other search problems in this class, and prove a variety of results both positive and negative.
On the positive side we show that Li's Range Avoidance algorithm \cite{Li} can be improved to give a reduction from Range Avoidance to a natural total search problem we call the Linear Ordering Principle or ``LOP'': given a circuit $\prec:\{0,1\}^n \times \{0,1\}^n \to \{0,1\}$ purportedly defining a total order on $\{0,1\}^n$, find either a witness that $\prec$ is not a total order or else a minimal element in the ordering. The problem LOP is quite interesting in its own right, as it defines a natural syntactic subclass ``$L_2^P$'' of $S_2^P$ which nonetheless maintains most of the interesting properties of $S_2^P$; in particular we show that $L_2^P$ contains $MA$ and that its exponential analogue ${L_2^E}$ requires $2^n/n$ size circuits. Both of these are consequences of our reduction from Range Avoidance to LOP.
On the negative side we prove that the algorithms developed in \cite{CHR,Li} cannot be extended to Strong Range Avoidance, a problem considered in the same paper which first introduced Range Avoidance \cite{KKMP}. In this problem we are given a circuit $C: \{0,1\}^n \setminus\{0^n\} \to \{0,1\}^n$, and once again seek a point outside its range. We give a separation in the decision tree (oracle) model showing that this problem cannot be solved in ${FP^{\Sigma_2^P}_{||}}$, which in particular rules out all of the new kinds of algorithms considered in \cite{CHR,Li}. This black box separation is derived from a novel depth 3 ${AC^0}$ circuit lower bound for a total search problem, which we believe is of independent interest from the perspective of circuit complexity: we show that unlike previous depth 3 lower bounds, ours cannot be proven by reduction from a decision problem, and thus requires new techniques specifically tailored to total search problems. Proving lower bounds of this kind was recently proposed by Vyas and Williams in the context of the original (Weak) Avoid problem.
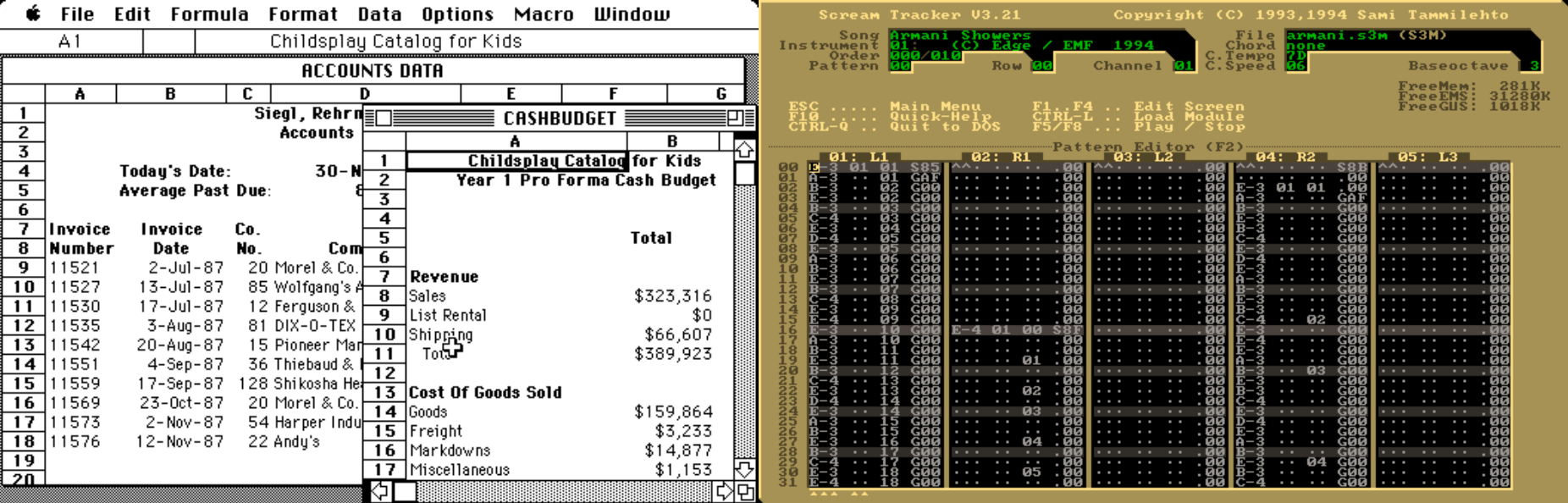
The long strange relationship between electronic music and business machines.
As a budding music nerd, I got pulled into the world of electronic music after discovering Scream Tracker in high school. I had been recording my various bands with a 4-track but wanted to try some more experimental directions. My summer job at the time was helping organize some logistical workbooks for the neurology department where my dad worked. It’s funny to look back at Scream Tracker and 90s-era Microsoft Excel next to each other. For me, computer music has always been doing clerical data entry into a spreadsheet.
Having grown up in the shadow of the business machine, electronic music has always had this bizarre bureaucratic dressing. Ironically, the dominant mode of transmitting creative ideas into computer music is the keyboard, and it’s not clear from context to which homonym I’m referring. Do I mean the one with letters or the one with white and black keys? Why not both?
Look at drum machines. We took our most visceral instruments—percussion you physically pummel to summon massive grooves—and put them in a box that looks like an answering machine.
And yet these boxes can move a club in ways a drummer never could.
Mechanical business machines could conjure the most intense human emotions. Our spreadsheet samplers and a single drum loop created an alien genre that still gets people moving today.
But it always seemed like these music tools were a technological crutch and that the real future of music would be bringing the sonic versatility of electronic music back to the old physical reality of banging on things to get people to dance. Wouldn’t people soon tire of going to shows to watch people turn knobs?
Ostensibly, I was admitted to graduate school to work on AI for music. I guess we didn’t call it AI at the time, because AI was a dirty word in the year 2000 (footnote It still should be a dirty word, damn it!). My lab had developed what my advisor, Neil Gershenfeld, called a “Digital Stradivarius.” Neil figured that as long as you could sample the sonic timbre of a genuine Stradivarius, you could use machine learning to synthesize the nuances of playing a real one. Bernd Schoner’s PhD used expectation maximization and some clever hardware to make a pretty nice-sounding digital cello. He called it a “marching cello” as it was far less bulky than its analog counterpart:
But as software improved, I quickly became disenchanted with musical hardware. More and more devices could be replaced by your laptop. By the early 2000s, I could, on the same computer, record and mix a rock band, make upbeat techno, and create live ambient music. Though die-hards hold onto their room-sized modular synthesizers, we crossed the laptop singularity decades ago.
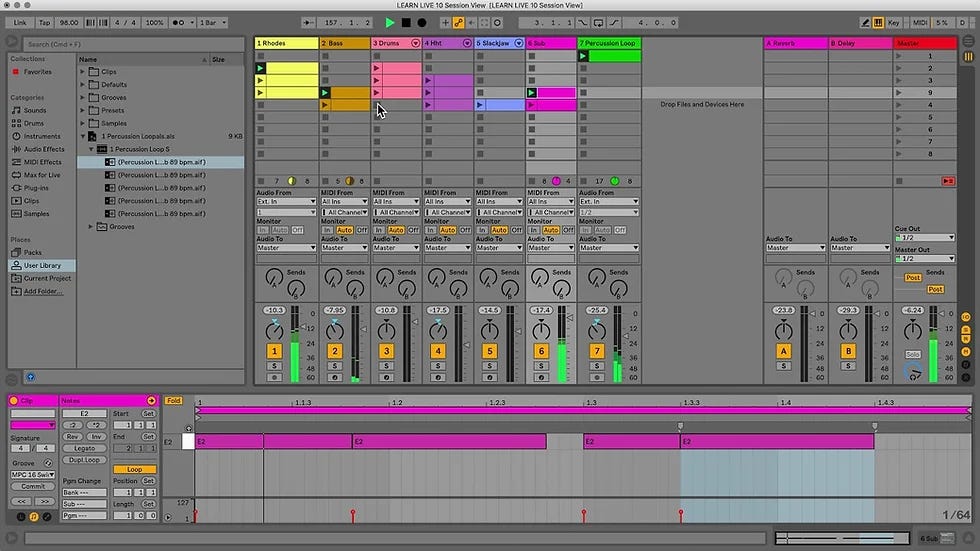
Fast forward to 2024, the most dominant tool for electronic music production and beyond is the software Ableton Live. I have been a committed Live user since the beta tests in 2001. Though it initially just played looping samples, it now has impressive synthesis engines, support for programming your own plug-ins, and a built-in search engine for managing your library of sounds.
25 years later, we don’t have a better marching cello, but we have an amazing Stradivarius sample pack. It turned out that samples were all you need. You didn’t need machine learning. And instead of a novel device for bowing and nuanced articulation, you still input commands like you did in 1999. Enter the data with a keyboard and mouse into a spreadsheet:
But if the future of music is the same as the future of the spreadsheet, what does that say about the future of AI and music? Maybe that means we should look at which areas LLMs are supposedly going to revolutionize and think about how to directly map those applications onto computer music.
As you, my dear readers, know, I don’t think LLMs are going to walk, talk, see, write, reproduce themselves, or be conscious of their existence. But I also don’t think they are useless. In particular, the most compelling and impressive application of large language models thus far has been code generation. The sorts of projects graduate students can build with GPT4 are beyond impressive. What would the analog be in music? As I wrote on Monday and hint at today, the most challenging part of modern digital audio is making sense of the infinite collection of synthesizer presets and sample packs.
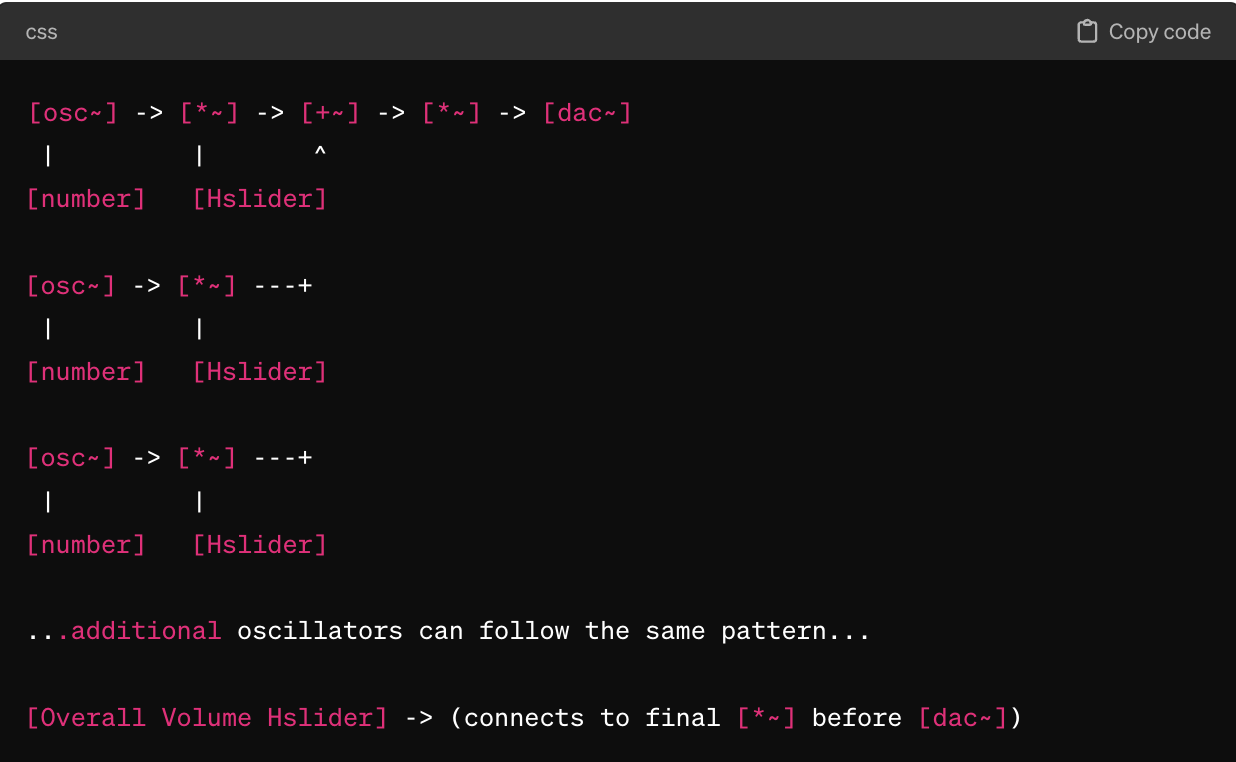
At its most abstract level, could we create a prompt system for synthesizers? People can make incredible music with the graphical programming language MaxMSP. Can we simplify creating MaxMSP patches with GPT4? MaxMSP is just code, after all! This isn’t that far away from what I can tell. GPT4 knows what pd is (it’s the open source version of MaxMSP), and it can sort of help you get started building patches. I asked it to create a pd patch of a simple additive synthesizer, and it gave me a long spiel and “a simplified textual diagram of what the patch might look like.”
Tightening this up seems pretty straightforward, doesn't it?
Moving from code to information retrieval, could we build better search tools for the vast collection of sounds we now have access to? Ableton Live ships with gigabytes of presets, and finding the one you have in mind can take hours. Can we build a chatbot that helps us navigate the infinite sea of sounds? As it exists now, the search capabilities in software like Ableton Live only index the keywords in the names of the presets. What if they could get access to more metadata? Perhaps search could then return a list of instruments and plugins associated with a natural language prompt. More ambitiously, what about sound search? Could we take a sample of music and suggest sample packs that might get you close to emulating the style? Bringing richer data to this search could open up endless creative possibilities.
Another idea that’s probably within our reach is converting existing songs into playable instruments. Ableton Live already has an “audio to midi” converter that takes sounds and converts the melody and rhythm into primitive computer music code. Could better AI tooling take a recording and produce a sampler instrument that recreates something that approximates the input’s nuance? Maybe we could upload a band’s recording, extract melodies and rhythms of the different players, and give continuous control parameters that the producer could manipulate. Where are we with source separation technology?
The issue with my wishlist is music remains a low-margin business. Listening, playing, and dancing to music are fundamental to our lives, but you’re not going to get a big VC check to innovate them. So a last question: Can you build the sorts of projects I’m asking about using cheap, open-source models? My guess is you can! And someone really should.
For our next favorite theorem, we look at the surprising power of provers who share entangled bits. If you can prove something to an arbitrarily computable verifier, then two entangled provers can convince a polynomial-time verifier.
MIP* = RE Zhengfeng Ji, Anand Natarajan, Thomas Vidick, John Wright and Henry Yuen
A quick tour:
A powerful prover convincing a skeptical computable deterministic verifier is another way of capturing computably enumerable (traditionally called recursively enumerable or RE). You can convince a verifier that a program halts by giving the halting time, and the verifier can simulate the machine for that many steps.
A powerful prover convincing a skeptical polytime deterministic verifier is another way of capturing the class NP, like giving a 3-coloring of a graph that can be easily checked.
If you allow the verifier to ask random questions, you can convince the verifier with high confidence that a graph is not colorable, or more generally any PSPACE problem.
If you add two separated provers that a skeptical probabilistic verifier can play off each other, the provers can convince the verifier that any problem in NEXP, non-deterministic exponential time.
One of many quantum variations of interactive proofs, MIP* has two provers that cannot communicate but have entangled quantum bits. This change could go either way:
The provers to coordinate their answers better and so they wouldn't convince the verifier for all the languages in NEXP
The verifier could ask more complex questions to the provers which they could answer using the entanglement, allowing the provers to convince the verifier for even more complex languages.
Turns out it's the later in a very strong way.
Ito and Vidick showed that you can create a protocol that prevents the provers coordinating better, recovering all problems in NEXP. Vidick and Wright showed you can ask more questions, showing that provers with entangled bits can convince a verifier of everything in NEEXP, non-deterministic double exponential time (\(2^{2^{n^c}}\)), already a proof too large for the verifier to even point into. The MIP* = RE paper takes that all the way to the computably enumerable sets, all the languages you would get with a classical prover convincing a deterministic verifier unrestricted by time.
By Lance Fortnow
For our next favorite theorem, we look at the surprising power of provers who share entangled bits. If you can prove something to an arbitrarily computable verifier, then two entangled provers can convince a polynomial-time verifier.
MIP* = RE Zhengfeng Ji, Anand Natarajan, Thomas Vidick, John Wright and Henry Yuen
A quick tour:
A powerful prover convincing a skeptical computable deterministic verifier is another way of capturing computably enumerable (traditionally called recursively enumerable or RE). You can convince a verifier that a program halts by giving the halting time, and the verifier can simulate the machine for that many steps.
A powerful prover convincing a skeptical polytime deterministic verifier is another way of capturing the class NP, like giving a 3-coloring of a graph that can be easily checked.
If you allow the verifier to ask random questions, you can convince the verifier with high confidence that a graph is not colorable, or more generally any PSPACE problem.
If you add two separated provers that a skeptical probabilistic verifier can play off each other, the provers can convince the verifier that any problem in NEXP, non-deterministic exponential time.
One of many quantum variations of interactive proofs, MIP* has two provers that cannot communicate but have entangled quantum bits. This change could go either way:
The provers to coordinate their answers better and so they wouldn't convince the verifier for all the languages in NEXP
The verifier could ask more complex questions to the provers which they could answer using the entanglement, allowing the provers to convince the verifier for even more complex languages.
Turns out it's the later in a very strong way.
Ito and Vidick showed that you can create a protocol that prevents the provers coordinating better, recovering all problems in NEXP. Vidick and Wright showed you can ask more questions, showing that provers with entangled bits can convince a verifier of everything in NEEXP, non-deterministic double exponential time (\(2^{2^{n^c}}\)), already a proof too large for the verifier to even point into. The MIP* = RE paper takes that all the way to the computably enumerable sets, all the languages you would get with a classical prover convincing a deterministic verifier unrestricted by time.
April 18-30, 2024 Vancouver, Canada sigact.org/tcsforall/ Submission deadline: April 28, 2024 Nomination deadline for TCS for All Spotlight Workshop and travel scholarships to attend STOC are on April 28th. Nominate your students and postdocs who will be in the job market in near future. Since 2018, TCS for All (previously TCS for Women) is supporting … Continue reading TCS for All Rising Star Workshop and Travel Scholarships
By shacharlovett
April 18-30, 2024 Vancouver, Canada https://sigact.org/tcsforall/ Submission deadline: April 28, 2024 Nomination deadline for TCS for All Spotlight Workshop and travel scholarships to attend STOC are on April 28th. Nominate your students and postdocs who will be in the job market in near future. Since 2018, TCS for All (previously TCS for Women) is supporting … Continue reading TCS for All Rising Star Workshop and Travel Scholarships
One of the elegant achievements in the history of proof theory is the
characterization of the provably total recursive functions of an arithmetical
theory by its proof-theoretic ordinal as a way to measure the time complexity
of the functions. Unfortunately, the machinery is not sufficiently fine-grained
to be applicable on the weak theories on the one hand and to capture the
bounded functions with bounded definitions of strong theories, on the other. In
this paper, we develop such a machinery to address the bounded theorems of both
strong and weak theories of arithmetic. In the first part, we provide a refined
version of ordinal analysis to capture the feasibly definable and bounded
functions that are provably total in $\mathrm{PA}+\bigcup_{\beta \prec \alpha}
\mathrm{TI}(\prec_{\beta})$, the extension of Peano arithmetic by transfinite
induction up to the ordinals below $\alpha$. Roughly speaking, we identify the
functions as the ones that are computable by a sequence of
$\mathrm{PV}$-provable polynomial time modifications on an initial polynomial
time value, where the computational steps are indexed by the ordinals below
$\alpha$, decreasing by the modifications. In the second part, and choosing $l
\leq k$, we use similar technique to capture the functions with bounded
definitions in the theory $T^k_2$ (resp. $S^k_2$) as the functions computable
by exponentially (resp. polynomially) long sequence of
$\mathrm{PV}_{k-l+1}$-provable reductions between $l$-turn games starting with
an explicit $\mathrm{PV}_{k-l+1}$-provable winning strategy for the first game.
One of the elegant achievements in the history of proof theory is the
characterization of the provably total recursive functions of an arithmetical
theory by its proof-theoretic ordinal as a way to measure the time complexity
of the functions. Unfortunately, the machinery is not sufficiently fine-grained
to be applicable on the weak theories on the one hand and to capture the
bounded functions with bounded definitions of strong theories, on the other. In
this paper, we develop such a machinery to address the bounded theorems of both
strong and weak theories of arithmetic. In the first part, we provide a refined
version of ordinal analysis to capture the feasibly definable and bounded
functions that are provably total in $\mathrm{PA}+\bigcup_{\beta \prec \alpha}
\mathrm{TI}(\prec_{\beta})$, the extension of Peano arithmetic by transfinite
induction up to the ordinals below $\alpha$. Roughly speaking, we identify the
functions as the ones that are computable by a sequence of
$\mathrm{PV}$-provable polynomial time modifications on an initial polynomial
time value, where the computational steps are indexed by the ordinals below
$\alpha$, decreasing by the modifications. In the second part, and choosing $l
\leq k$, we use similar technique to capture the functions with bounded
definitions in the theory $T^k_2$ (resp. $S^k_2$) as the functions computable
by exponentially (resp. polynomially) long sequence of
$\mathrm{PV}_{k-l+1}$-provable reductions between $l$-turn games starting with
an explicit $\mathrm{PV}_{k-l+1}$-provable winning strategy for the first game.
Automaton learning is a domain in which the target system is inferred by the
automaton learning algorithm in the form of an automaton, by synthesizing a
finite number of inputs and their corresponding outputs. Automaton learning
makes use of a Minimally Adequate Teacher (MAT). The learner learns the target
system by posing membership queries to the MAT. In this chapter, I have
provided completely solved examples of automaton learning algorithms. According
to the best of my knowledge these are not available in any other source.
Automaton learning is a domain in which the target system is inferred by the
automaton learning algorithm in the form of an automaton, by synthesizing a
finite number of inputs and their corresponding outputs. Automaton learning
makes use of a Minimally Adequate Teacher (MAT). The learner learns the target
system by posing membership queries to the MAT. In this chapter, I have
provided completely solved examples of automaton learning algorithms. According
to the best of my knowledge these are not available in any other source.
We prove optimal concentration of measure for lifted functions on high
dimensional expanders (HDX). Let $X$ be a $k$-dimensional HDX. We show for any
$i\leq k$ and $f:X(i)\to [0,1]$: \[\Pr_{s\in
X(k)}\left[\left|\underset{{t\subseteq
s}}{\mathbb{E}}[f(t)]-\mu\right|\geq\varepsilon\right]\leq
exp\left(-\varepsilon^2\frac{k}{i}\right).\] Using this fact, we prove that
high dimensional expanders are reverse hypercontractive, a powerful functional
inequality from discrete analysis implying that for any sets $A,B \subset
X(k)$, the probability a $\rho$-correlated pair passes between them is at least
\[\Pr_{s,s' \sim T_\rho}[s \in A, s' \in B] \geq \Pr[A]^{O(1)} \Pr[B]^{O(1)}.\]
Our results hold under weak spectral assumptions on $X$. Namely we prove
exponential concentration of measure for any complex below the `Trickling-Down
Threshold' (beyond which concentration may be arbitrarily poor), and optimal
concentration for $\sqrt{k}$-skeletons of such complexes. We also show optimal
bounds for the top dimension of stronger HDX among other settings. We leverage
our inequalities to prove several new agreement testing theorems on high
dimensional expanders, including a new 99%-regime test for subsets, and a
variant of the `Z-test' achieving inverse exponential soundness under the
stronger assumption of $\ell_\infty$-expansion. The latter gives rise to the
first optimal testers beyond the complete complex and products, a stepping
stone toward the use of HDX in strong soundness PCPs. We also give applications
within expansion, analysis, combinatorics, and coding theory, including a proof
that two-sided HDX have optimal geometric overlap (giving the first explicit
bounded-degree construction), near-optimal double samplers, new
super-exponential degree lower bounds for certain HDX, distance-amplified
list-decodable and locally testable codes, a Frankl-R\"odl Theorem and more.
We prove optimal concentration of measure for lifted functions on high
dimensional expanders (HDX). Let $X$ be a $k$-dimensional HDX. We show for any
$i\leq k$ and $f:X(i)\to [0,1]$: \[\Pr_{s\in
X(k)}\left[\left|\underset{{t\subseteq
s}}{\mathbb{E}}[f(t)]-\mu\right|\geq\varepsilon\right]\leq
exp\left(-\varepsilon^2\frac{k}{i}\right).\] Using this fact, we prove that
high dimensional expanders are reverse hypercontractive, a powerful functional
inequality from discrete analysis implying that for any sets $A,B \subset
X(k)$, the probability a $\rho$-correlated pair passes between them is at least
\[\Pr_{s,s' \sim T_\rho}[s \in A, s' \in B] \geq \Pr[A]^{O(1)} \Pr[B]^{O(1)}.\]
Our results hold under weak spectral assumptions on $X$. Namely we prove
exponential concentration of measure for any complex below the `Trickling-Down
Threshold' (beyond which concentration may be arbitrarily poor), and optimal
concentration for $\sqrt{k}$-skeletons of such complexes. We also show optimal
bounds for the top dimension of stronger HDX among other settings. We leverage
our inequalities to prove several new agreement testing theorems on high
dimensional expanders, including a new 99%-regime test for subsets, and a
variant of the `Z-test' achieving inverse exponential soundness under the
stronger assumption of $\ell_\infty$-expansion. The latter gives rise to the
first optimal testers beyond the complete complex and products, a stepping
stone toward the use of HDX in strong soundness PCPs. We also give applications
within expansion, analysis, combinatorics, and coding theory, including a proof
that two-sided HDX have optimal geometric overlap (giving the first explicit
bounded-degree construction), near-optimal double samplers, new
super-exponential degree lower bounds for certain HDX, distance-amplified
list-decodable and locally testable codes, a Frankl-R\"odl Theorem and more.
The ZH calculus is a graphical language for quantum computation reasoning.
The phase-free variant offers a simple set of generators that guarantee
universality. ZH calculus is effective in MBQC and analysis of quantum circuits
constructed with the universal gate set Toffoli+H. While circuits naturally
translate to ZH diagrams, finding an ancilla-free circuit equivalent to a given
diagram is hard. Here, we show that circuit extraction for phase-free ZH
calculus is ${\mathord{\#}\mathrm P}$-hard, extending the existing result for
ZX calculus. Another problem believed to be hard is comparing whether two
diagrams represent the same process. We show that two closely related problems
are $\mathrm{NP}^{\mathord{\#}\mathrm P}$-complete. The first problem is: given
two processes represented as diagrams, determine the existence of a
computational basis state on which they equalize. The second problem is
checking whether the matrix representation of a given diagram contains an entry
equal to a given number. Our proof adapts the proof of Cook-Levin theorem to a
reduction from a non-deterministic Turing Machine with access to
${\mathord{\#}\mathrm P}$ oracle.
The ZH calculus is a graphical language for quantum computation reasoning.
The phase-free variant offers a simple set of generators that guarantee
universality. ZH calculus is effective in MBQC and analysis of quantum circuits
constructed with the universal gate set Toffoli+H. While circuits naturally
translate to ZH diagrams, finding an ancilla-free circuit equivalent to a given
diagram is hard. Here, we show that circuit extraction for phase-free ZH
calculus is ${\mathord{\#}\mathrm P}$-hard, extending the existing result for
ZX calculus. Another problem believed to be hard is comparing whether two
diagrams represent the same process. We show that two closely related problems
are $\mathrm{NP}^{\mathord{\#}\mathrm P}$-complete. The first problem is: given
two processes represented as diagrams, determine the existence of a
computational basis state on which they equalize. The second problem is
checking whether the matrix representation of a given diagram contains an entry
equal to a given number. Our proof adapts the proof of Cook-Levin theorem to a
reduction from a non-deterministic Turing Machine with access to
${\mathord{\#}\mathrm P}$ oracle.
We design polynomial size, constant depth (namely, $\mathsf{AC}^0$)
arithmetic formulae for the greatest common divisor (GCD) of two polynomials,
as well as the related problems of the discriminant, resultant, B\'ezout
coefficients, squarefree decomposition, and the inversion of structured
matrices like Sylvester and B\'ezout matrices. Our GCD algorithm extends to any
number of polynomials. Previously, the best known arithmetic formulae for these
problems required super-polynomial size, regardless of depth.
These results are based on new algorithmic techniques to compute various
symmetric functions in the roots of polynomials, as well as manipulate the
multiplicities of these roots, without having access to them. These techniques
allow $\mathsf{AC}^0$ computation of a large class of linear and polynomial
algebra problems, which include the above as special cases.
We extend these techniques to problems whose inputs are multivariate
polynomials, which are represented by $\mathsf{AC}^0$ arithmetic circuits. Here
too we solve problems such as computing the GCD and squarefree decomposition in
$\mathsf{AC}^0$.
We design polynomial size, constant depth (namely, $\mathsf{AC}^0$)
arithmetic formulae for the greatest common divisor (GCD) of two polynomials,
as well as the related problems of the discriminant, resultant, B\'ezout
coefficients, squarefree decomposition, and the inversion of structured
matrices like Sylvester and B\'ezout matrices. Our GCD algorithm extends to any
number of polynomials. Previously, the best known arithmetic formulae for these
problems required super-polynomial size, regardless of depth.
These results are based on new algorithmic techniques to compute various
symmetric functions in the roots of polynomials, as well as manipulate the
multiplicities of these roots, without having access to them. These techniques
allow $\mathsf{AC}^0$ computation of a large class of linear and polynomial
algebra problems, which include the above as special cases.
We extend these techniques to problems whose inputs are multivariate
polynomials, which are represented by $\mathsf{AC}^0$ arithmetic circuits. Here
too we solve problems such as computing the GCD and squarefree decomposition in
$\mathsf{AC}^0$.
Authors: Felicia Lucke, Ali Momeni, Daniël Paulusma, Siani Smith
The $d$-Cut problem is to decide if a graph has an edge cut such that each
vertex has at most $d$ neighbours at the opposite side of the cut. If $d=1$, we
obtain the intensively studied Matching Cut problem. The $d$-Cut problem has
been studied as well, but a systematic study for special graph classes was
lacking. We initiate such a study and consider classes of bounded diameter,
bounded radius and $H$-free graphs. We prove that for all $d\geq 2$, $d$-Cut is
polynomial-time solvable for graphs of diameter $2$, $(P_3+P_4)$-free graphs
and $P_5$-free graphs. These results extend known results for $d=1$. However,
we also prove several NP-hardness results for $d$-Cut that contrast known
polynomial-time results for $d=1$. Our results lead to full dichotomies for
bounded diameter and bounded radius and to almost-complete dichotomies for
$H$-free graphs.
The $d$-Cut problem is to decide if a graph has an edge cut such that each
vertex has at most $d$ neighbours at the opposite side of the cut. If $d=1$, we
obtain the intensively studied Matching Cut problem. The $d$-Cut problem has
been studied as well, but a systematic study for special graph classes was
lacking. We initiate such a study and consider classes of bounded diameter,
bounded radius and $H$-free graphs. We prove that for all $d\geq 2$, $d$-Cut is
polynomial-time solvable for graphs of diameter $2$, $(P_3+P_4)$-free graphs
and $P_5$-free graphs. These results extend known results for $d=1$. However,
we also prove several NP-hardness results for $d$-Cut that contrast known
polynomial-time results for $d=1$. Our results lead to full dichotomies for
bounded diameter and bounded radius and to almost-complete dichotomies for
$H$-free graphs.
We study the complexity of approximating the permanent of a positive
semidefinite matrix $A\in \mathbb{C}^{n\times n}$.
1. We design a new approximation algorithm for $\mathrm{per}(A)$ with
approximation ratio $e^{(0.9999 + \gamma)n}$, exponentially improving upon the
current best bound of $e^{(1+\gamma-o(1))n}$ [AGOS17,YP22]. Here, $\gamma
\approx 0.577$ is Euler's constant.
2. We prove that it is NP-hard to approximate $\mathrm{per}(A)$ within a
factor $e^{(\gamma-\epsilon)n}$ for any $\epsilon>0$. This is the first
exponential hardness of approximation for this problem. Along the way, we prove
optimal hardness of approximation results for the $\|\cdot\|_{2\to q}$ ``norm''
problem of a matrix for all $-1 < q < 2$.
We study the complexity of approximating the permanent of a positive
semidefinite matrix $A\in \mathbb{C}^{n\times n}$.
1. We design a new approximation algorithm for $\mathrm{per}(A)$ with
approximation ratio $e^{(0.9999 + \gamma)n}$, exponentially improving upon the
current best bound of $e^{(1+\gamma-o(1))n}$ [AGOS17,YP22]. Here, $\gamma
\approx 0.577$ is Euler's constant.
2. We prove that it is NP-hard to approximate $\mathrm{per}(A)$ within a
factor $e^{(\gamma-\epsilon)n}$ for any $\epsilon>0$. This is the first
exponential hardness of approximation for this problem. Along the way, we prove
optimal hardness of approximation results for the $\|\cdot\|_{2\to q}$ ``norm''
problem of a matrix for all $-1 < q < 2$.
Authors: Toluwanimi O. Odemuyiwa, Joel S. Emer, John D. Owens
In this work, we propose a unified abstraction for graph algorithms: the
Extended General Einsums language, or EDGE. The EDGE language expresses graph
algorithms in the language of tensor algebra, providing a rigorous, succinct,
and expressive mathematical framework. EDGE leverages two ideas: (1) the
well-known foundations provided by the graph-matrix duality, where a graph is
simply a 2D tensor, and (2) the power and expressivity of Einsum notation in
the tensor algebra world. In this work, we describe our design goals for EDGE
and walk through the extensions we add to Einsums to support more complex
operations common in graph algorithms. Additionally, we provide a few examples
of how to express graph algorithms in our proposed notation. We hope that a
single, mathematical notation for graph algorithms will (1) allow researchers
to more easily compare different algorithms and different implementations of a
graph algorithm; (2) enable developers to factor complexity by separating the
concerns of what to compute (described with the extended Einsum notation) from
the lower level details of how to compute; and (3) enable the discovery of
different algorithmic variants of a problem through algebraic manipulations and
transformations on a given EDGE expression.
In this work, we propose a unified abstraction for graph algorithms: the
Extended General Einsums language, or EDGE. The EDGE language expresses graph
algorithms in the language of tensor algebra, providing a rigorous, succinct,
and expressive mathematical framework. EDGE leverages two ideas: (1) the
well-known foundations provided by the graph-matrix duality, where a graph is
simply a 2D tensor, and (2) the power and expressivity of Einsum notation in
the tensor algebra world. In this work, we describe our design goals for EDGE
and walk through the extensions we add to Einsums to support more complex
operations common in graph algorithms. Additionally, we provide a few examples
of how to express graph algorithms in our proposed notation. We hope that a
single, mathematical notation for graph algorithms will (1) allow researchers
to more easily compare different algorithms and different implementations of a
graph algorithm; (2) enable developers to factor complexity by separating the
concerns of what to compute (described with the extended Einsum notation) from
the lower level details of how to compute; and (3) enable the discovery of
different algorithmic variants of a problem through algebraic manipulations and
transformations on a given EDGE expression.
A set family ${\cal F}$ is called intersecting if every two members of ${\cal
F}$ intersect, and it is called uniform if all members of ${\cal F}$ share a
common size. A uniform family ${\cal F} \subseteq \binom{[n]}{k}$ of
$k$-subsets of $[n]$ is $\varepsilon$-far from intersecting if one has to
remove more than $\varepsilon \cdot \binom{n}{k}$ of the sets of ${\cal F}$ to
make it intersecting. We study the property testing problem that given query
access to a uniform family ${\cal F} \subseteq \binom{[n]}{k}$, asks to
distinguish between the case that ${\cal F}$ is intersecting and the case that
it is $\varepsilon$-far from intersecting. We prove that for every fixed
integer $r$, the problem admits a non-adaptive two-sided error tester with
query complexity $O(\frac{\ln n}{\varepsilon})$ for $\varepsilon \geq \Omega(
(\frac{k}{n})^r)$ and a non-adaptive one-sided error tester with query
complexity $O(\frac{\ln k}{\varepsilon})$ for $\varepsilon \geq \Omega(
(\frac{k^2}{n})^r)$. The query complexities are optimal up to the logarithmic
terms. For $\varepsilon \geq \Omega( (\frac{k^2}{n})^2)$, we further provide a
non-adaptive one-sided error tester with optimal query complexity of
$O(\frac{1}{\varepsilon})$. Our findings show that the query complexity of the
problem differs substantially from that of testing intersectingness of
non-uniform families, studied recently by Chen, De, Li, Nadimpalli, and
Servedio (ITCS, 2024).
A set family ${\cal F}$ is called intersecting if every two members of ${\cal
F}$ intersect, and it is called uniform if all members of ${\cal F}$ share a
common size. A uniform family ${\cal F} \subseteq \binom{[n]}{k}$ of
$k$-subsets of $[n]$ is $\varepsilon$-far from intersecting if one has to
remove more than $\varepsilon \cdot \binom{n}{k}$ of the sets of ${\cal F}$ to
make it intersecting. We study the property testing problem that given query
access to a uniform family ${\cal F} \subseteq \binom{[n]}{k}$, asks to
distinguish between the case that ${\cal F}$ is intersecting and the case that
it is $\varepsilon$-far from intersecting. We prove that for every fixed
integer $r$, the problem admits a non-adaptive two-sided error tester with
query complexity $O(\frac{\ln n}{\varepsilon})$ for $\varepsilon \geq \Omega(
(\frac{k}{n})^r)$ and a non-adaptive one-sided error tester with query
complexity $O(\frac{\ln k}{\varepsilon})$ for $\varepsilon \geq \Omega(
(\frac{k^2}{n})^r)$. The query complexities are optimal up to the logarithmic
terms. For $\varepsilon \geq \Omega( (\frac{k^2}{n})^2)$, we further provide a
non-adaptive one-sided error tester with optimal query complexity of
$O(\frac{1}{\varepsilon})$. Our findings show that the query complexity of the
problem differs substantially from that of testing intersectingness of
non-uniform families, studied recently by Chen, De, Li, Nadimpalli, and
Servedio (ITCS, 2024).
Given functions $f$ and $g$ defined on the subset lattice of order $n$, their
min-sum subset convolution, defined for all $S \subseteq [n]$ as \[
(f \star g)(S) = \min_{T \subseteq S}\:\big(f(T) + g(S \setminus T)\big), \]
is a fundamental tool in parameterized algorithms. However, since its na\"ive
$O(3^n)$-time evaluation is also the fastest known, it has been used only in
settings where the input functions have a bounded integer range $\{-M, \ldots,
M\}$. In this case, the running time becomes $\tilde O(2^n M)$ by resorting to
fast subset convolution in the sum-product ring. This is disadvantageous due to
the dependence on $M$, limiting its practicality.
In this light, we study whether the problem admits an $(1 +
\varepsilon)$-approximation scheme in time independent of $M$. Our main result
is the first $\tilde O(2^\frac{3n}{2} / \sqrt{\varepsilon})$-time algorithm for
the $(1 + \varepsilon)$-approximate min-sum subset convolution. To show its
applicability, we present $(1 + \varepsilon)$-approximation schemes in the same
exponential time bound for several NP-hard problems using this convolution,
such as the minimum-cost $k$-coloring problem -- in time $\tilde
O(2^\frac{3n}{2} / \sqrt{\varepsilon})$, and the prize-collecting Steiner tree
problem -- in time $\tilde O(2^\frac{3s^+}{2} / \sqrt{\varepsilon})$, where $n$
is the number of vertices and $s^+$ is the number of proper potential
terminals. We also discuss two other applications in computational biology.
Our algorithms lie at the intersection of two lines of research that have
been considered separately: $\textit{sequence}$ and $\textit{subset}$
convolutions in semi-rings. In particular, we extend the recent framework of
Bringmann, K\"unnemann, and W\k{e}grzycki [STOC 2019] to the context of subset
convolutions.
Given functions $f$ and $g$ defined on the subset lattice of order $n$, their
min-sum subset convolution, defined for all $S \subseteq [n]$ as \[
(f \star g)(S) = \min_{T \subseteq S}\:\big(f(T) + g(S \setminus T)\big), \]
is a fundamental tool in parameterized algorithms. However, since its na\"ive
$O(3^n)$-time evaluation is also the fastest known, it has been used only in
settings where the input functions have a bounded integer range $\{-M, \ldots,
M\}$. In this case, the running time becomes $\tilde O(2^n M)$ by resorting to
fast subset convolution in the sum-product ring. This is disadvantageous due to
the dependence on $M$, limiting its practicality.
In this light, we study whether the problem admits an $(1 +
\varepsilon)$-approximation scheme in time independent of $M$. Our main result
is the first $\tilde O(2^\frac{3n}{2} / \sqrt{\varepsilon})$-time algorithm for
the $(1 + \varepsilon)$-approximate min-sum subset convolution. To show its
applicability, we present $(1 + \varepsilon)$-approximation schemes in the same
exponential time bound for several NP-hard problems using this convolution,
such as the minimum-cost $k$-coloring problem -- in time $\tilde
O(2^\frac{3n}{2} / \sqrt{\varepsilon})$, and the prize-collecting Steiner tree
problem -- in time $\tilde O(2^\frac{3s^+}{2} / \sqrt{\varepsilon})$, where $n$
is the number of vertices and $s^+$ is the number of proper potential
terminals. We also discuss two other applications in computational biology.
Our algorithms lie at the intersection of two lines of research that have
been considered separately: $\textit{sequence}$ and $\textit{subset}$
convolutions in semi-rings. In particular, we extend the recent framework of
Bringmann, K\"unnemann, and W\k{e}grzycki [STOC 2019] to the context of subset
convolutions.
In this expository note we show that the learning parities with noise (LPN)
assumption is robust to weak dependencies in the noise distribution of small
batches of samples. This provides a partial converse to the linearization
technique of [AG11]. The material in this note is drawn from a recent work by
the authors [GMR24], where the robustness guarantee was a key component in a
cryptographic separation between reinforcement learning and supervised
learning.
In this expository note we show that the learning parities with noise (LPN)
assumption is robust to weak dependencies in the noise distribution of small
batches of samples. This provides a partial converse to the linearization
technique of [AG11]. The material in this note is drawn from a recent work by
the authors [GMR24], where the robustness guarantee was a key component in a
cryptographic separation between reinforcement learning and supervised
learning.
We give a distribution-free testing algorithm for decision lists with
$\tilde{O}(n^{11/12}/\varepsilon^3)$ queries. This is the first sublinear
algorithm for this problem, which shows that, unlike halfspaces, testing is
strictly easier than learning for decision lists. Complementing the algorithm,
we show that any distribution-free tester for decision lists must make
$\tilde{\Omega}(\sqrt{n})$ queries, or draw $\tilde{\Omega}(n)$ samples when
the algorithm is sample-based.
We give a distribution-free testing algorithm for decision lists with
$\tilde{O}(n^{11/12}/\varepsilon^3)$ queries. This is the first sublinear
algorithm for this problem, which shows that, unlike halfspaces, testing is
strictly easier than learning for decision lists. Complementing the algorithm,
we show that any distribution-free tester for decision lists must make
$\tilde{\Omega}(\sqrt{n})$ queries, or draw $\tilde{\Omega}(n)$ samples when
the algorithm is sample-based.
Authors: Nicole Immorlica, Brendan Lucier, Markus Mobius, James Siderius
We introduce a model of online algorithms subject to strict constraints on
data retention. An online learning algorithm encounters a stream of data
points, one per round, generated by some stationary process. Crucially, each
data point can request that it be removed from memory $m$ rounds after it
arrives. To model the impact of removal, we do not allow the algorithm to store
any information or calculations between rounds other than a subset of the data
points (subject to the retention constraints). At the conclusion of the stream,
the algorithm answers a statistical query about the full dataset. We ask: what
level of performance can be guaranteed as a function of $m$?
We illustrate this framework for multidimensional mean estimation and linear
regression problems. We show it is possible to obtain an exponential
improvement over a baseline algorithm that retains all data as long as
possible. Specifically, we show that $m = \textsc{Poly}(d, \log(1/\epsilon))$
retention suffices to achieve mean squared error $\epsilon$ after observing
$O(1/\epsilon)$ $d$-dimensional data points. This matches the error bound of
the optimal, yet infeasible, algorithm that retains all data forever. We also
show a nearly matching lower bound on the retention required to guarantee error
$\epsilon$. One implication of our results is that data retention laws are
insufficient to guarantee the right to be forgotten even in a non-adversarial
world in which firms merely strive to (approximately) optimize the performance
of their algorithms.
Our approach makes use of recent developments in the multidimensional random
subset sum problem to simulate the progression of stochastic gradient descent
under a model of adversarial noise, which may be of independent interest.
We introduce a model of online algorithms subject to strict constraints on
data retention. An online learning algorithm encounters a stream of data
points, one per round, generated by some stationary process. Crucially, each
data point can request that it be removed from memory $m$ rounds after it
arrives. To model the impact of removal, we do not allow the algorithm to store
any information or calculations between rounds other than a subset of the data
points (subject to the retention constraints). At the conclusion of the stream,
the algorithm answers a statistical query about the full dataset. We ask: what
level of performance can be guaranteed as a function of $m$?
We illustrate this framework for multidimensional mean estimation and linear
regression problems. We show it is possible to obtain an exponential
improvement over a baseline algorithm that retains all data as long as
possible. Specifically, we show that $m = \textsc{Poly}(d, \log(1/\epsilon))$
retention suffices to achieve mean squared error $\epsilon$ after observing
$O(1/\epsilon)$ $d$-dimensional data points. This matches the error bound of
the optimal, yet infeasible, algorithm that retains all data forever. We also
show a nearly matching lower bound on the retention required to guarantee error
$\epsilon$. One implication of our results is that data retention laws are
insufficient to guarantee the right to be forgotten even in a non-adversarial
world in which firms merely strive to (approximately) optimize the performance
of their algorithms.
Our approach makes use of recent developments in the multidimensional random
subset sum problem to simulate the progression of stochastic gradient descent
under a model of adversarial noise, which may be of independent interest.
Authors: Gabriel Chuang, Oussama Hanguir, Clifford Stein
In the process of redistricting, one important metric is the number of
competitive districts, that is, districts where both parties have a reasonable
chance of winning a majority of votes. Competitive districts are important for
achieving proportionality, responsiveness, and other desirable qualities; some
states even directly list competitiveness in their legally-codified districting
requirements. In this work, we discuss the problem of drawing plans with at
least a fixed number of competitive districts. In addition to the standard,
``vote-band'' measure of competitivenesss (i.e., how close was the last
election?), we propose a measure that explicitly considers ``swing voters'' -
the segment of the population that may choose to vote either way, or not vote
at all, in a given election. We present two main, contrasting results. First,
from a computational complexity perspective, we show that the task of drawing
plans with competitive districts is NP-hard, even on very natural instances
where the districting task itself is easy (e.g., small rectangular grids of
population-balanced cells). Second, however, we show that a simple
hill-climbing procedure can in practice find districtings on real states in
which all the districts are competitive. We present the results of the latter
on the precinct-level graphs of the U.S. states of North Carolina and Arizona,
and discuss trade-offs between competitiveness and other desirable qualities.
In the process of redistricting, one important metric is the number of
competitive districts, that is, districts where both parties have a reasonable
chance of winning a majority of votes. Competitive districts are important for
achieving proportionality, responsiveness, and other desirable qualities; some
states even directly list competitiveness in their legally-codified districting
requirements. In this work, we discuss the problem of drawing plans with at
least a fixed number of competitive districts. In addition to the standard,
``vote-band'' measure of competitivenesss (i.e., how close was the last
election?), we propose a measure that explicitly considers ``swing voters'' -
the segment of the population that may choose to vote either way, or not vote
at all, in a given election. We present two main, contrasting results. First,
from a computational complexity perspective, we show that the task of drawing
plans with competitive districts is NP-hard, even on very natural instances
where the districting task itself is easy (e.g., small rectangular grids of
population-balanced cells). Second, however, we show that a simple
hill-climbing procedure can in practice find districtings on real states in
which all the districts are competitive. We present the results of the latter
on the precinct-level graphs of the U.S. states of North Carolina and Arizona,
and discuss trade-offs between competitiveness and other desirable qualities.
The Traveling Tournament Problem (TTP) is a well-known benchmark problem in
the field of tournament timetabling, which asks us to design a double
round-robin schedule such that each pair of teams plays one game in each
other's home venue, minimizing the total distance traveled by all $n$ teams
($n$ is even). TTP-$k$ is the problem with one more constraint that each team
can have at most $k$-consecutive home games or away games. In this paper, we
investigate schedules for TTP-$k$ and analyze the approximation ratio of the
solutions. Most previous schedules were constructed based on a Hamiltonian
cycle of the graph. We will propose a novel construction based on a $k$-cycle
packing. Then, combining our $k$-cycle packing schedule with the Hamiltonian
cycle schedule, we obtain improved approximation ratios for TTP-$k$ with deep
analysis. The case where $k=3$, TTP-3, is one of the most investigated cases.
We improve the approximation ratio of TTP-3 from $(1.667+\varepsilon)$ to
$(1.598+\varepsilon)$, for any $\varepsilon>0$. For TTP-$4$, we improve the
approximation ratio from $(1.750+\varepsilon)$ to $(1.700+\varepsilon)$. By a
refined analysis of the Hamiltonian cycle construction, we also improve the
approximation ratio of TTP-$k$ from $(\frac{5k-7}{2k}+\varepsilon)$ to
$(\frac{5k^2-4k+3}{2k(k+1)}+\varepsilon)$ for any constant $k\geq 5$. Our
methods can be extended to solve a variant called LDTTP-$k$ (TTP-$k$ where all
teams are allocated on a straight line). We show that the $k$-cycle packing
construction can achieve an approximation ratio of
$(\frac{3k-3}{2k-1}+\varepsilon)$, which improves the approximation ratio of
LDTTP-3 from $4/3$ to $(6/5+\varepsilon)$.
The Traveling Tournament Problem (TTP) is a well-known benchmark problem in
the field of tournament timetabling, which asks us to design a double
round-robin schedule such that each pair of teams plays one game in each
other's home venue, minimizing the total distance traveled by all $n$ teams
($n$ is even). TTP-$k$ is the problem with one more constraint that each team
can have at most $k$-consecutive home games or away games. In this paper, we
investigate schedules for TTP-$k$ and analyze the approximation ratio of the
solutions. Most previous schedules were constructed based on a Hamiltonian
cycle of the graph. We will propose a novel construction based on a $k$-cycle
packing. Then, combining our $k$-cycle packing schedule with the Hamiltonian
cycle schedule, we obtain improved approximation ratios for TTP-$k$ with deep
analysis. The case where $k=3$, TTP-3, is one of the most investigated cases.
We improve the approximation ratio of TTP-3 from $(1.667+\varepsilon)$ to
$(1.598+\varepsilon)$, for any $\varepsilon>0$. For TTP-$4$, we improve the
approximation ratio from $(1.750+\varepsilon)$ to $(1.700+\varepsilon)$. By a
refined analysis of the Hamiltonian cycle construction, we also improve the
approximation ratio of TTP-$k$ from $(\frac{5k-7}{2k}+\varepsilon)$ to
$(\frac{5k^2-4k+3}{2k(k+1)}+\varepsilon)$ for any constant $k\geq 5$. Our
methods can be extended to solve a variant called LDTTP-$k$ (TTP-$k$ where all
teams are allocated on a straight line). We show that the $k$-cycle packing
construction can achieve an approximation ratio of
$(\frac{3k-3}{2k-1}+\varepsilon)$, which improves the approximation ratio of
LDTTP-3 from $4/3$ to $(6/5+\varepsilon)$.
How does the internal computation of an ML model transform inputs into predictions?
Consider a standard ResNet50 model trained on an image classification task. Is it possible to understand how the convolution filters in this model transform an input image to its predicted label? Or, how the attention heads in GPT-3 contribute to next-token predictions? Grasping how these model components—architectural “building blocks” such as filters or heads—collectively shape model behavior (including model failures) is difficult. After all, deep networks are largely black-boxes—complex computation graphs with highly non-linear interactions among model components.
Motivated by this challenge, a line of work in interpretability aims to shed light on internal model computation by characterizing the functionality of individual components, e.g., curve detectors and object-specific filters in vision models, or knowledge neurons and induction heads in language models. The approaches developed as part of this line of work aim to “zoom in” on specific model behaviors and/or components in a variety of ways.
In our recent paper, we take a different, complementary perspective. Instead of “zooming in” on individual components, we study how model components collectively combine to yield model predictions. Specifically, we ask:
How do changes to model components collectively change individual predictions?
Explicitly Modeling Model Computation
To tackle the question above, we introduce a task called component modeling. The goal of component modeling is to build a simple and interpretable estimator of how a model’s output would change in response to interventions, or ablations, made to its components. Intuitively, the key idea here (illustrated in the figure below) is that if we truly understood how model components contribute to a prediction, we should be able to estimate how the prediction would change if we were to change some components:
♦
Our paper focuses on a special “linear” case of component modeling, which we call component attribution. As shown below, a component attribution for a given model prediction first assigns a score to each model component, and then estimates the counterfactual effect of ablating a set of components as the sum of their corresponding scores:
♦
Component attributions are simple—they decompose a given prediction into additive contributions from each model component. They are also interpretable, in that the “score” assigned to a component signifies the “contribution” of that component to the prediction of interest (while abstracting away the complexity of the model’s internal computation).
Aside: We’ve explored a similar line of thinking—understanding via prediction—in our work on datamodeling, where the goal is to predict model behavior as a function of training data. Component models and component attribution can be seen as analogs of datamodels and data attribution (or linear datamodeling) in “component space,” rather than “training dataset space.”
Estimating Component Attributions via Regression (COAR)
A priori, it’s unclear whether component attributions are expressive enough to capture the (inherently non-linear) map from components to predictions in deep networks. However, we find that on vision models (e.g., ImageNet ViTs) and language models (e.g., Phi-2) one can actually compute accurate component attribution—that is, linearity suffices to predict the effect of component ablations (!), as shown below:
♦
To compute these attributions (i.e., the coefficient vector \(w\) above), we propose a simple method—called COAR (Component Attribution via Regression)—that turns this task into a standard supervised learning problem, and solves it in two steps:
Construct a dataset of component ablations. We randomly ablate random subsets of components and record both the ablation itself, as well as how the model’s output changes for each example of interest. This gives us a dataset of component ablations and their corresponding effects on the model predictions.
Fit a linear regression model. We fit a linear model that takes as input an “ablation vector” (a binary vector that encodes the ablated components) and predicts the ablation effect on a given example’s prediction. The learned weights of this linear model serve as our component attributions, quantifying the contribution of each component to the model’s prediction.
That’s it! Both steps of our component attribution method, COAR, are scalable and general, i.e., completely agnostic to model architecture. This allows us to stress-test the effectiveness of COAR attributions in a systematic manner.
Are COAR attributions accurate?
Let’s come back to our ResNet-50, trained on the ImageNet dataset. We’ll view this model as a composition of 22,720 components, each corresponding to a convolutional filter. Can we use COAR to predict how this model will respond to component ablations (in this case, ablation corresponds to zeroing out the parameters of a given set of filters)?
To answer this question, we use COAR to estimate component attribution for each of the 50,000 examples in the ImageNet validation set. The result is a set of 50,000 component attributions–each attribution estimating how every component contributes to the model’s prediction on the corresponding ImageNet example.
To see whether the resulting attributions are indeed valid, we simply check whether component attributions accurately estimate the effect of (randomly) ablating random subsets of components on model outputs.
♦
For example, the figure above focuses on a single ImageNet example. Each dot corresponds to a (random) set of model components. The y value of a given dot is the counterfactual effect of ablating that set of components (i.e., setting the corresponding parameters to zero); the x axis is our estimate of that counterfactual effect, as given by the example’s component attribution. The ground-truth and attribution-estimated effects of (random) component ablations exhibit a high correlation of 0.70, meaning that at least for this example, component attributions are quite good at predicting model behavior!
In the figure below, we turn this into an aggregate analysis. That is, we evaluate the average correlation between the ground-truth ablation effects and attribution-based estimates over all validation examples—to test the limits of COAR, we also vary the fractions of components ablated and study how COAR’s performance changes. As baselines, we adapt several notions of “component importance” (some used by prior work, and some that we designed ourselves) to the component attribution setting:
♦
Overall, we find that COAR consistently outperforms multiple attribution baselines by a large margin across datasets and models.
For a more thorough evaluation of COAR attributions, check out our paper. We stress-test there the predictive power of COAR attributions on several other model architectures (e.g., CLIP ViTs, Phi-2, and even simple MLPs) and tasks (e.g., next-token prediction and zero-shot classification).
Up next: applications
What can we actually do with these component attributions? Do they have any practical utility? In our upcoming post, we’ll explore how COAR attributions enable effective model editing. Specifically, we will dive there into the connection between attribution and model editing, and apply COAR to two editing tasks. Stay tuned!
How does the internal computation of an ML model transform inputs into predictions?
Consider a standard ResNet50 model trained on an image classification task. Is it possible to understand how the convolution filters in this model transform an input image to its predicted label? Or, how the attention heads in GPT-3 contribute to next-token predictions? Grasping how these model components—architectural “building blocks” such as filters or heads—collectively shape model behavior (includingmodelfailures) is difficult. After all, deep networks are largely black-boxes—complex computation graphs with highly non-linear interactions among model components.
Motivated by this challenge, a line of work in interpretability aims to shed light on internal model computation by characterizing the functionality of individual components, e.g., curve detectors and object-specific filters in vision models, or knowledge neurons and induction heads in language models. The approaches developed as part of this line of work aim to “zoom in” on specific model behaviors and/or components in a variety of ways.
In our recent paper, we take a different, complementary perspective. Instead of “zooming in” on individual components, we study how model components collectively combine to yield model predictions. Specifically, we ask:
How do changes to model components collectively change individual predictions?
Explicitly Modeling Model Computation
To tackle the question above, we introduce a task called component modeling. The goal of component modeling is to build a simple and interpretable estimator of how a model’s output would change in response to interventions, or ablations, made to its components. Intuitively, the key idea here (illustrated in the figure below) is that if we truly understood how model components contribute to a prediction, we should be able to estimate how the prediction would change if we were to change some components:
Our paper focuses on a special “linear” case of component modeling, which we call component attribution. As shown below, a component attribution for a given model prediction first assigns a score to each model component, and then estimates the counterfactual effect of ablating a set of components as the sum of their corresponding scores:
Component attributions are simple—they decompose a given prediction into additive contributions from each model component. They are also interpretable, in that the “score” assigned to a component signifies the “contribution” of that component to the prediction of interest (while abstracting away the complexity of the model’s internal computation).
Aside: We’ve explored a similar line of thinking—understanding via prediction—in our work on datamodeling, where the goal is to predict model behavior as a function of training data. Component models and component attribution can be seen as analogs of datamodels and data attribution (or linear datamodeling) in “component space,” rather than “training dataset space.”
Estimating Component Attributions via Regression (COAR)
A priori, it’s unclear whether component attributions are expressive enough to capture the (inherently non-linear) map from components to predictions in deep networks. However, we find that on vision models (e.g., ImageNet ViTs) and language models (e.g., Phi-2) one can actually compute accurate component attribution—that is, linearity suffices to predict the effect of component ablations (!), as shown below:
To compute these attributions (i.e., the coefficient vector \(w\) above), we propose a simple method—called COAR (Component Attribution via Regression)—that turns this task into a standard supervised learning problem, and solves it in two steps:
Construct a dataset of component ablations. We randomly ablate random subsets of components and record both the ablation itself, as well as how the model’s output changes for each example of interest. This gives us a dataset of component ablations and their corresponding effects on the model predictions.
Fit a linear regression model. We fit a linear model that takes as input an “ablation vector” (a binary vector that encodes the ablated components) and predicts the ablation effect on a given example’s prediction. The learned weights of this linear model serve as our component attributions, quantifying the contribution of each component to the model’s prediction.
That’s it! Both steps of our component attribution method, COAR, are scalable and general, i.e., completely agnostic to model architecture. This allows us to stress-test the effectiveness of COAR attributions in a systematic manner.
Are COAR attributions accurate?
Let’s come back to our ResNet-50, trained on the ImageNet dataset. We’ll view this model as a composition of 22,720 components, each corresponding to a convolutional filter. Can we use COAR to predict how this model will respond to component ablations (in this case, ablation corresponds to zeroing out the parameters of a given set of filters)?
To answer this question, we use COAR to estimate component attribution for each of the 50,000 examples in the ImageNet validation set. The result is a set of 50,000 component attributions–each attribution estimating how every component contributes to the model’s prediction on the corresponding ImageNet example.
To see whether the resulting attributions are indeed valid, we simply check whether component attributions accurately estimate the effect of (randomly) ablating random subsets of components on model outputs.
For example, the figure above focuses on a single ImageNet example. Each dot corresponds to a (random) set of model components. The y value of a given dot is the counterfactual effect of ablating that set of components (i.e., setting the corresponding parameters to zero); the x axis is our estimate of that counterfactual effect, as given by the example’s component attribution. The ground-truth and attribution-estimated effects of (random) component ablations exhibit a high correlation of 0.70, meaning that at least for this example, component attributions are quite good at predicting model behavior!
In the figure below, we turn this into an aggregate analysis. That is, we evaluate the average correlation between the ground-truth ablation effects and attribution-based estimates over all validation examples—to test the limits of COAR, we also vary the fractions of components ablated and study how COAR’s performance changes. As baselines, we adapt several notions of “component importance” (some used by prior work, and some that we designed ourselves) to the component attribution setting:
Overall, we find that COAR consistently outperforms multiple attribution baselines by a large margin across datasets and models.
For a more thorough evaluation of COAR attributions, check out our paper. We stress-test there the predictive power of COAR attributions on several other model architectures (e.g., CLIP ViTs, Phi-2, and even simple MLPs) and tasks (e.g., next-token prediction and zero-shot classification).
Up next: applications
What can we actually do with these component attributions? Do they have any practical utility? In our upcoming post, we’ll explore how COAR attributions enable effective model editing. Specifically, we will dive there into the connection between attribution and model editing, and apply COAR to two editing tasks. Stay tuned!
Inria Lille and the University of Lille in France have a funding opportunity for a PhD student under the supervision of Antoine Amarilli, Mikaël Monet, and Sylvain Salvati. The PhD will start in fall 2024 for a duration of 3 years. The PhD is about width measures for tractable query evaluation on probabilistic databases; it […]
Inria Lille and the University of Lille in France have a funding opportunity for a PhD student under the supervision of Antoine Amarilli, Mikaël Monet, and Sylvain Salvati. The PhD will start in fall 2024 for a duration of 3 years. The PhD is about width measures for tractable query evaluation on probabilistic databases; it relates to counting complexity, graph theory, formal languages, and logic.
Guest post by the organizers of TCS for All (previously TCS Women). You are cordially invited to our TCS for All Spotlight Workshop! The workshop will be held on June 24, 2024, at 12:30 pm – 2 pm, and 4:15 pm – 5:45 pm in Vancouver, Canada as part of the 56th Symposium on Theory […]
Guest post by the organizers of TCS for All (previously TCS Women).
You are cordially invited to our TCS for All Spotlight Workshop! The workshop will be held on June 24, 2024, at 12:30 pm – 2 pm, and 4:15 pm – 5:45 pm in Vancouver, Canada as part of the 56th Symposium on Theory of Computing (STOC) and TheoryFest! The workshop is open to all.
More information about the workshop would be made available here: https://sigact.org/tcsforall/. In particular, we would like to highlight the TCS for All Travel Scholarships (deadline April 28th) and a call for nominations for Rising Stars talks at the workshop (deadline April 28th). More information on those are below.
Hope to see you in Vancouver!
TCS for All Travel Scholarship:
TCS for All Travel Scholarships are intended for researchers at the beginning of their career. This scholarship is being made available for minorities in TCS, and anyone who identifies as such is welcome to apply; this scholarship is open to both US and international students. Preference will be given to students at the beginning of their studies. If we have sufficient funding, we will give awards to more senior students and possibly even postdocs.
To apply, you will need to fill out the following form by April 28th, 2024 (11:59 pm PDT) in which you provide basic information about yourself, an estimate of your expenses, and a brief statement:
In addition, you will need to have your advisor (or department head or other faculty mentor if you do not yet have an advisor) send a letter of support to tcswomen@gmail.com by April 28th. Your advisor’s letter should also describe the availability of other travel funds. Note for advisors: Specifics about alternative funding are very helpful. Statements like “funding is tight” are not very helpful. This letter should be sent with the subject line “support letter for [your name]”. This is very important. Your application is not complete without this letter.
Late applications (after April 28th) will not be accepted. You will be notified about your status by May 5th, which is prior to the STOC early registration deadline and hotel cut-off deadline.
Notes: Receipts will be required for all travel awards, and reimbursements will be made after the conference. Food or visa expenses will not be reimbursed.
Nominations for Rising Star talks:
We invite nominations for speakers in our Rising Star talks at the TCS for All Spotlight Workshop at STOC 2024. To be eligible, your nominee has to be a senior PhD student with expected graduation no later than August 2024, or a postdoc in theoretical computer science (all topics represented at STOC are welcome), an underrepresented minority, and not a speaker at a previous TCS Women Spotlight Workshop. Preference will be given to speakers who are currently on the job market for postdoctoral/faculty positions, or who expect to be on the job market in Fall 2024.
Authors: MIT Hardness Group, Erik D. Demaine, Holden Hall, Jeffery Li
We prove NP-hardness and #P-hardness of Tetris clearing (clearing an initial
board using a given sequence of pieces) with the Super Rotation System (SRS),
even when the pieces are limited to any two of the seven Tetris piece types.
This result is the first advance on a question posed twenty years ago: which
piece sets are easy vs. hard? All previous Tetris NP-hardness proofs used five
of the seven piece types. We also prove ASP-completeness of Tetris clearing,
using three piece types, as well as versions of 3-Partition and Numerical
3-Dimensional Matching where all input integers are distinct. Finally, we prove
NP-hardness of Tetris survival and clearing under the "hard drops only" and
"20G" modes, using two piece types, improving on a previous "hard drops only"
result that used five piece types.
We prove NP-hardness and #P-hardness of Tetris clearing (clearing an initial
board using a given sequence of pieces) with the Super Rotation System (SRS),
even when the pieces are limited to any two of the seven Tetris piece types.
This result is the first advance on a question posed twenty years ago: which
piece sets are easy vs. hard? All previous Tetris NP-hardness proofs used five
of the seven piece types. We also prove ASP-completeness of Tetris clearing,
using three piece types, as well as versions of 3-Partition and Numerical
3-Dimensional Matching where all input integers are distinct. Finally, we prove
NP-hardness of Tetris survival and clearing under the "hard drops only" and
"20G" modes, using two piece types, improving on a previous "hard drops only"
result that used five piece types.
Authors: MIT Hardness Group, Hayashi Ani, Erik D. Demaine, Holden Hall, Matias Korman
We prove PSPACE-hardness for fifteen games in the Super Mario Bros. 2D
platforming video game series. Previously, only the original Super Mario Bros.
was known to be PSPACE-hard (FUN 2016), though several of the games we study
were known to be NP-hard (FUN 2014). Our reductions build door gadgets with
open, close, and traverse traversals, in each case using mechanics unique to
the game. While some of our door constructions are similar to those from FUN
2016, those for Super Mario Bros. 2, Super Mario Land 2, Super Mario World 2,
and the New Super Mario Bros. series are quite different; notably, the Super
Mario Bros. 2 door is extremely difficult. Doors remain elusive for just two 2D
Mario games (Super Mario Land and Super Mario Run); we prove that these games
are at least NP-hard.
We prove PSPACE-hardness for fifteen games in the Super Mario Bros. 2D
platforming video game series. Previously, only the original Super Mario Bros.
was known to be PSPACE-hard (FUN 2016), though several of the games we study
were known to be NP-hard (FUN 2014). Our reductions build door gadgets with
open, close, and traverse traversals, in each case using mechanics unique to
the game. While some of our door constructions are similar to those from FUN
2016, those for Super Mario Bros. 2, Super Mario Land 2, Super Mario World 2,
and the New Super Mario Bros. series are quite different; notably, the Super
Mario Bros. 2 door is extremely difficult. Doors remain elusive for just two 2D
Mario games (Super Mario Land and Super Mario Run); we prove that these games
are at least NP-hard.
Authors: Jesse Beisegel, Nina Chiarelli, Ekkehard Köhler, Martin Milanič, Peter Muršič, Robert Scheffler
We propose a novel way of generalizing the class of interval graphs, via a
graph width parameter called the simultaneous interval number. This parameter
is related to the simultaneous representation problem for interval graphs and
defined as the smallest number $d$ of labels such that the graph admits a
$d$-simultaneous interval representation, that is, an assignment of intervals
and label sets to the vertices such that two vertices are adjacent if and only
if the corresponding intervals, as well as their label sets, intersect. We show
that this parameter is $\mathsf{NP}$-hard to compute and give several bounds
for the parameter, showing in particular that it is sandwiched between
pathwidth and linear mim-width. For classes of graphs with bounded parameter
values, assuming that the graph is equipped with a simultaneous interval
representation with a constant number of labels, we give $\mathsf{FPT}$
algorithms for the clique, independent set, and dominating set problems, and
hardness results for the independent dominating set and coloring problems. The
$\mathsf{FPT}$ results for independent set and dominating set are for the
simultaneous interval number plus solution size. In contrast, both problems are
known to be $\mathsf{W}[1]$-hard for linear mim-width plus solution size.
We propose a novel way of generalizing the class of interval graphs, via a
graph width parameter called the simultaneous interval number. This parameter
is related to the simultaneous representation problem for interval graphs and
defined as the smallest number $d$ of labels such that the graph admits a
$d$-simultaneous interval representation, that is, an assignment of intervals
and label sets to the vertices such that two vertices are adjacent if and only
if the corresponding intervals, as well as their label sets, intersect. We show
that this parameter is $\mathsf{NP}$-hard to compute and give several bounds
for the parameter, showing in particular that it is sandwiched between
pathwidth and linear mim-width. For classes of graphs with bounded parameter
values, assuming that the graph is equipped with a simultaneous interval
representation with a constant number of labels, we give $\mathsf{FPT}$
algorithms for the clique, independent set, and dominating set problems, and
hardness results for the independent dominating set and coloring problems. The
$\mathsf{FPT}$ results for independent set and dominating set are for the
simultaneous interval number plus solution size. In contrast, both problems are
known to be $\mathsf{W}[1]$-hard for linear mim-width plus solution size.
The capacitated tree cover problem with edge loads is a variant of the tree
cover problem, where we are given facility opening costs, edge costs and loads,
as well as vertex loads. We try to find a tree cover of minimum cost such that
the total edge and vertex load of each tree does not exceed a given bound. We
present an $\mathcal{O}(m\log n)$ time 3-approximation algorithm for this
problem.
This is achieved by starting with a certain LP formulation. We give a
combinatorial algorithm that solves the LP optimally in time $\mathcal{O}(m\log
n)$. Then, we show that a linear time rounding and splitting technique leads to
an integral solution that costs at most 3 times as much as the LP solution.
Finally, we prove that the integrality gap of the LP is $3$, which shows that
we can not improve the rounding step in general.
The capacitated tree cover problem with edge loads is a variant of the tree
cover problem, where we are given facility opening costs, edge costs and loads,
as well as vertex loads. We try to find a tree cover of minimum cost such that
the total edge and vertex load of each tree does not exceed a given bound. We
present an $\mathcal{O}(m\log n)$ time 3-approximation algorithm for this
problem.
This is achieved by starting with a certain LP formulation. We give a
combinatorial algorithm that solves the LP optimally in time $\mathcal{O}(m\log
n)$. Then, we show that a linear time rounding and splitting technique leads to
an integral solution that costs at most 3 times as much as the LP solution.
Finally, we prove that the integrality gap of the LP is $3$, which shows that
we can not improve the rounding step in general.
In project management, a project is typically described as an
activity-on-edge network (AOE network), where each activity / job is
represented as an edge of some network $N$ (which is a DAG). Some jobs must be
finished before others can be started, as described by the topology structure
of $N$. It is known that job $j_i$ in normal speed would require $b_i$ days to
be finished after it is started. Given the network $N$ with the associated edge
lengths $b_1,\ldots,b_m$, the duration of the project is determined, which
equals the length of the critical path (namely, the longest path) of $N$.
To speed up the project (i.e. reduce the duration), the manager can crash a
few jobs (namely, reduce the length of the corresponding edges) by investing
extra resources into that job. However, the time for completing $j_i$ has a
lower bound due to technological limits -- it requires at least $a_i$ days to
be completed. Moreover, it is expensive to buy resources. Given $N$ and an
integer $k\geq 1$, the $k$-crashing problem asks the minimum amount of
resources required to speed up the project by $k$ days. We show a simple and
efficient algorithm with an approximation ratio
$\frac{1}{1}+\ldots+\frac{1}{k}$ for this problem.
We also study a related problem called $k$-LIS, in which we are given a
sequence $\omega$ of numbers and we aim to find $k$ disjoint increasing
subsequence of $\omega$ with the largest total length. We show a
$(1-\frac{1}{e})$-approximation algorithm which is simple and efficient.
In project management, a project is typically described as an
activity-on-edge network (AOE network), where each activity / job is
represented as an edge of some network $N$ (which is a DAG). Some jobs must be
finished before others can be started, as described by the topology structure
of $N$. It is known that job $j_i$ in normal speed would require $b_i$ days to
be finished after it is started. Given the network $N$ with the associated edge
lengths $b_1,\ldots,b_m$, the duration of the project is determined, which
equals the length of the critical path (namely, the longest path) of $N$.
To speed up the project (i.e. reduce the duration), the manager can crash a
few jobs (namely, reduce the length of the corresponding edges) by investing
extra resources into that job. However, the time for completing $j_i$ has a
lower bound due to technological limits -- it requires at least $a_i$ days to
be completed. Moreover, it is expensive to buy resources. Given $N$ and an
integer $k\geq 1$, the $k$-crashing problem asks the minimum amount of
resources required to speed up the project by $k$ days. We show a simple and
efficient algorithm with an approximation ratio
$\frac{1}{1}+\ldots+\frac{1}{k}$ for this problem.
We also study a related problem called $k$-LIS, in which we are given a
sequence $\omega$ of numbers and we aim to find $k$ disjoint increasing
subsequence of $\omega$ with the largest total length. We show a
$(1-\frac{1}{e})$-approximation algorithm which is simple and efficient.
Authors: Florin Manea, Jonas Richardsen, Markus L. Schmid
For two strings u, v over some alphabet A, we investigate the problem of
embedding u into w as a subsequence under the presence of generalised gap
constraints. A generalised gap constraint is a triple (i, j, C_{i, j}), where 1
<= i < j <= |u| and C_{i, j} is a subset of A^*. Embedding u as a subsequence
into v such that (i, j, C_{i, j}) is satisfied means that if u[i] and u[j] are
mapped to v[k] and v[l], respectively, then the induced gap v[k + 1..l - 1]
must be a string from C_{i, j}. This generalises the setting recently
investigated in [Day et al., ISAAC 2022], where only gap constraints of the
form C_{i, i + 1} are considered, as well as the setting from [Kosche et al.,
RP 2022], where only gap constraints of the form C_{1, |u|} are considered.
We show that subsequence matching under generalised gap constraints is
NP-hard, and we complement this general lower bound with a thorough
(parameterised) complexity analysis. Moreover, we identify several efficiently
solvable subclasses that result from restricting the interval structure induced
by the generalised gap constraints.
For two strings u, v over some alphabet A, we investigate the problem of
embedding u into w as a subsequence under the presence of generalised gap
constraints. A generalised gap constraint is a triple (i, j, C_{i, j}), where 1
<= i < j <= |u| and C_{i, j} is a subset of A^*. Embedding u as a subsequence
into v such that (i, j, C_{i, j}) is satisfied means that if u[i] and u[j] are
mapped to v[k] and v[l], respectively, then the induced gap v[k + 1..l - 1]
must be a string from C_{i, j}. This generalises the setting recently
investigated in [Day et al., ISAAC 2022], where only gap constraints of the
form C_{i, i + 1} are considered, as well as the setting from [Kosche et al.,
RP 2022], where only gap constraints of the form C_{1, |u|} are considered.
We show that subsequence matching under generalised gap constraints is
NP-hard, and we complement this general lower bound with a thorough
(parameterised) complexity analysis. Moreover, we identify several efficiently
solvable subclasses that result from restricting the interval structure induced
by the generalised gap constraints.
We study the Short Path Packing problem which asks, given a graph $G$,
integers $k$ and $\ell$, and vertices $s$ and $t$, whether there exist $k$
pairwise internally vertex-disjoint $s$-$t$ paths of length at most $\ell$. The
problem has been proven to be NP-hard and fixed-parameter tractable
parameterized by $k$ and $\ell$. Most previous research on this problem has
been theoretical with limited practical implemetations. We present an exact
FPT-algorithm based on a search-tree approach in combination with greedy
localization. While its worst case runtime complexity of $(k\cdot
\ell^2)^{k\cdot \ell}\cdot n^{O(1)}$ is larger than the state of the art, the
nature of search-tree algorithms allows for a broad range of potential
optimizations. We exploit this potential by presenting techniques for input
preprocessing, early detection of trivial and infeasible instances, and
strategic selection of promising subproblems. Those approaches were implemented
and heavily tested on a large dataset of diverse graphs. The results show that
our heuristic improvements are very effective and that for the majority of
instances, we can achieve fast runtimes.
We study the Short Path Packing problem which asks, given a graph $G$,
integers $k$ and $\ell$, and vertices $s$ and $t$, whether there exist $k$
pairwise internally vertex-disjoint $s$-$t$ paths of length at most $\ell$. The
problem has been proven to be NP-hard and fixed-parameter tractable
parameterized by $k$ and $\ell$. Most previous research on this problem has
been theoretical with limited practical implemetations. We present an exact
FPT-algorithm based on a search-tree approach in combination with greedy
localization. While its worst case runtime complexity of $(k\cdot
\ell^2)^{k\cdot \ell}\cdot n^{O(1)}$ is larger than the state of the art, the
nature of search-tree algorithms allows for a broad range of potential
optimizations. We exploit this potential by presenting techniques for input
preprocessing, early detection of trivial and infeasible instances, and
strategic selection of promising subproblems. Those approaches were implemented
and heavily tested on a large dataset of diverse graphs. The results show that
our heuristic improvements are very effective and that for the majority of
instances, we can achieve fast runtimes.
Authors: Sara Giuliani, Shunsuke Inenaga, Zsuzsanna Lipták, Giuseppe Romana, Marinella Sciortino, Cristian Urbina
A bit catastrophe, loosely defined, is when a change in just one character of
a string causes a significant change in the size of the compressed string. We
study this phenomenon for the Burrows-Wheeler Transform (BWT), a string
transform at the heart of several of the most popular compressors and aligners
today. The parameter determining the size of the compressed data is the number
of equal-letter runs of the BWT, commonly denoted $r$.
We exhibit infinite families of strings in which insertion, deletion, resp.
substitution of one character increases $r$ from constant to $\Theta(\log n)$,
where $n$ is the length of the string. These strings can be interpreted both as
examples for an increase by a multiplicative or an additive $\Theta(\log
n)$-factor. As regards multiplicative factor, they attain the upper bound given
by Akagi, Funakoshi, and Inenaga [Inf & Comput. 2023] of $O(\log n \log r)$,
since here $r=O(1)$.
We then give examples of strings in which insertion, deletion, resp.
substitution of a character increases $r$ by a $\Theta(\sqrt{n})$ additive
factor. These strings significantly improve the best known lower bound for an
additive factor of $\Omega(\log n)$ [Giuliani et al., SOFSEM 2021].
A bit catastrophe, loosely defined, is when a change in just one character of
a string causes a significant change in the size of the compressed string. We
study this phenomenon for the Burrows-Wheeler Transform (BWT), a string
transform at the heart of several of the most popular compressors and aligners
today. The parameter determining the size of the compressed data is the number
of equal-letter runs of the BWT, commonly denoted $r$.
We exhibit infinite families of strings in which insertion, deletion, resp.
substitution of one character increases $r$ from constant to $\Theta(\log n)$,
where $n$ is the length of the string. These strings can be interpreted both as
examples for an increase by a multiplicative or an additive $\Theta(\log
n)$-factor. As regards multiplicative factor, they attain the upper bound given
by Akagi, Funakoshi, and Inenaga [Inf & Comput. 2023] of $O(\log n \log r)$,
since here $r=O(1)$.
We then give examples of strings in which insertion, deletion, resp.
substitution of a character increases $r$ by a $\Theta(\sqrt{n})$ additive
factor. These strings significantly improve the best known lower bound for an
additive factor of $\Omega(\log n)$ [Giuliani et al., SOFSEM 2021].
We study the problem of private vector mean estimation in the shuffle model
of privacy where $n$ users each have a unit vector $v^{(i)} \in\mathbb{R}^d$.
We propose a new multi-message protocol that achieves the optimal error using
$\tilde{\mathcal{O}}\left(\min(n\varepsilon^2,d)\right)$ messages per user.
Moreover, we show that any (unbiased) protocol that achieves optimal error
requires each user to send $\Omega(\min(n\varepsilon^2,d)/\log(n))$ messages,
demonstrating the optimality of our message complexity up to logarithmic
factors. Additionally, we study the single-message setting and design a
protocol that achieves mean squared error
$\mathcal{O}(dn^{d/(d+2)}\varepsilon^{-4/(d+2)})$. Moreover, we show that any
single-message protocol must incur mean squared error $\Omega(dn^{d/(d+2)})$,
showing that our protocol is optimal in the standard setting where $\varepsilon
= \Theta(1)$. Finally, we study robustness to malicious users and show that
malicious users can incur large additive error with a single shuffler.
We study the problem of private vector mean estimation in the shuffle model
of privacy where $n$ users each have a unit vector $v^{(i)} \in\mathbb{R}^d$.
We propose a new multi-message protocol that achieves the optimal error using
$\tilde{\mathcal{O}}\left(\min(n\varepsilon^2,d)\right)$ messages per user.
Moreover, we show that any (unbiased) protocol that achieves optimal error
requires each user to send $\Omega(\min(n\varepsilon^2,d)/\log(n))$ messages,
demonstrating the optimality of our message complexity up to logarithmic
factors. Additionally, we study the single-message setting and design a
protocol that achieves mean squared error
$\mathcal{O}(dn^{d/(d+2)}\varepsilon^{-4/(d+2)})$. Moreover, we show that any
single-message protocol must incur mean squared error $\Omega(dn^{d/(d+2)})$,
showing that our protocol is optimal in the standard setting where $\varepsilon
= \Theta(1)$. Finally, we study robustness to malicious users and show that
malicious users can incur large additive error with a single shuffler.
Authors: Tvrtko Tadić, Cassiano Becker, Jennifer Neville
Random Projections have been widely used to generate embeddings for various
graph tasks due to their computational efficiency. The majority of applications
have been justified through the Johnson-Lindenstrauss Lemma. In this paper, we
take a step further and investigate how well dot product and cosine similarity
are preserved by Random Projections. Our analysis provides new theoretical
results, identifies pathological cases, and tests them with numerical
experiments. We find that, for nodes of lower or higher degrees, the method
produces especially unreliable embeddings for the dot product, regardless of
whether the adjacency or the (normalized version) transition is used. With
respect to the statistical noise introduced by Random Projections, we show that
cosine similarity produces remarkably more precise approximations.
Random Projections have been widely used to generate embeddings for various
graph tasks due to their computational efficiency. The majority of applications
have been justified through the Johnson-Lindenstrauss Lemma. In this paper, we
take a step further and investigate how well dot product and cosine similarity
are preserved by Random Projections. Our analysis provides new theoretical
results, identifies pathological cases, and tests them with numerical
experiments. We find that, for nodes of lower or higher degrees, the method
produces especially unreliable embeddings for the dot product, regardless of
whether the adjacency or the (normalized version) transition is used. With
respect to the statistical noise introduced by Random Projections, we show that
cosine similarity produces remarkably more precise approximations.
Authors: Cynthia Dwork, Kristjan Greenewald, Manish Raghavan
The US Decennial Census provides valuable data for both research and policy
purposes. Census data are subject to a variety of disclosure avoidance
techniques prior to release in order to preserve respondent confidentiality.
While many are interested in studying the impacts of disclosure avoidance
methods on downstream analyses, particularly with the introduction of
differential privacy in the 2020 Decennial Census, these efforts are limited by
a critical lack of data: The underlying "microdata," which serve as necessary
input to disclosure avoidance methods, are kept confidential.
In this work, we aim to address this limitation by providing tools to
generate synthetic microdata solely from published Census statistics, which can
then be used as input to any number of disclosure avoidance algorithms for the
sake of evaluation and carrying out comparisons. We define a principled
distribution over microdata given published Census statistics and design
algorithms to sample from this distribution. We formulate synthetic data
generation in this context as a knapsack-style combinatorial optimization
problem and develop novel algorithms for this setting. While the problem we
study is provably hard, we show empirically that our methods work well in
practice, and we offer theoretical arguments to explain our performance.
Finally, we verify that the data we produce are "close" to the desired ground
truth.
The US Decennial Census provides valuable data for both research and policy
purposes. Census data are subject to a variety of disclosure avoidance
techniques prior to release in order to preserve respondent confidentiality.
While many are interested in studying the impacts of disclosure avoidance
methods on downstream analyses, particularly with the introduction of
differential privacy in the 2020 Decennial Census, these efforts are limited by
a critical lack of data: The underlying "microdata," which serve as necessary
input to disclosure avoidance methods, are kept confidential.
In this work, we aim to address this limitation by providing tools to
generate synthetic microdata solely from published Census statistics, which can
then be used as input to any number of disclosure avoidance algorithms for the
sake of evaluation and carrying out comparisons. We define a principled
distribution over microdata given published Census statistics and design
algorithms to sample from this distribution. We formulate synthetic data
generation in this context as a knapsack-style combinatorial optimization
problem and develop novel algorithms for this setting. While the problem we
study is provably hard, we show empirically that our methods work well in
practice, and we offer theoretical arguments to explain our performance.
Finally, we verify that the data we produce are "close" to the desired ground
truth.
For those who don’t yet know from their other social media: a week ago the cryptographer Yilei Chen posted a preprint, eprint.iacr.org/2024/555, claiming to give a polynomial-time quantum algorithm to solve lattice problems. For example, it claims to solve the GapSVP problem, which asks to approximate the length of the shortest nonzero vector in a […]
For those who don’t yet know from their other social media: a week ago the cryptographer Yilei Chen posted a preprint, eprint.iacr.org/2024/555, claiming to give a polynomial-time quantum algorithm to solve lattice problems. For example, it claims to solve the GapSVP problem, which asks to approximate the length of the shortest nonzero vector in a given n-dimensional lattice, to within an approximation ratio of ~n4.5. The best approximation ratio previously known to be achievable in classical or quantum polynomial time was exponential in n.
If it’s correct, this is an extremely big deal. It doesn’t quite break the main lattice-based cryptosystems, but it would put those cryptosystems into a precarious position, vulnerable to a mere further polynomial improvement in the approximation factor. And, as we learned from the recent NIST competition, if the lattice-based and LWE-based systems were to fall, then we really don’t have many great candidates left for post-quantum public-key cryptography! On top of that, a full quantum break of LWE (which, again, Chen is not claiming) would lay waste (in a world with scalable QCs, of course) to a large fraction of the beautiful sandcastles that classical and quantum cryptographers have built up over the last couple decades—everything from Fully Homomorphic Encryption schemes, to Mahadev’s protocol for proving the output of any quantum computation to a classical skeptic.
So on the one hand, this would substantially enlarge the scope of exponential quantum speedups beyond what we knew a week ago: yet more reason to try to build scalable QCs! But on the other hand, it could also fuel an argument for coordinating to slow down the race to scalable fault-tolerant QCs, until the world can get its cryptographic house into better order. (Of course, as we’ve seen with the many proposals to slow down AI scaling, this might or might not be possible.)
So then, is the paper correct? I don’t know. It’s very obviously a serious effort by a serious researcher, a world away from the P=NP proofs that fill my inbox every day. But it might fail anyway. I’ve asked the world experts in quantum algorithms for lattice problems, and they’ve been looking at it, and none of them is ready yet to render a verdict. The central difficulty is that the algorithm is convoluted, and involves new tools that seem to come from left field, including complex Gaussian functions, the windowed quantum Fourier transform, and Karst waves (whatever those are). The algorithm has 9 phases by the author’s count. In my own perusal, I haven’t yet extracted even a high-level intuition—I can’t tell any little story like for Shor’s algorithm, e.g. “first you reduce factoring to period-finding, then you solve period-finding by applying a Fourier transform to a vector of amplitudes.”
So, the main purpose of this post is simply to throw things open to commenters! I’m happy to provide a public clearinghouse for questions and comments about the preprint, if those studying it would like that. You can even embed LaTeX in your comments, as will probably be needed to get anywhere.
Unrelated Update: Connor Tabarrok and his friends just put a podcast with me up on YouTube, in which they interview me in my office at UT Austin about watermarking of large language models and other AI safety measures.
Authors: Carlos V. G. C. Lima, Thiago Marcilon, Pedro Paulo de Medeiros
The subject of graph convexity is well explored in the literature, the
so-called interval convexities above all. In this work, we explore the cycle
convexity, whose interval function is $I(S) = S \cup \{u \mid G[S \cup \{u\}]$
has a cycle containing $u\}$. In this convexity, we prove that the decision
problems associated to the parameters rank and convexity number are in
\NP-complete and \W[1]-hard when parameterized by the solution size. We also
prove that to determine whether the percolation time of a graph is at least $k$
is \NP-complete, but polynomial for cacti or when $k\leq2$
The subject of graph convexity is well explored in the literature, the
so-called interval convexities above all. In this work, we explore the cycle
convexity, whose interval function is $I(S) = S \cup \{u \mid G[S \cup \{u\}]$
has a cycle containing $u\}$. In this convexity, we prove that the decision
problems associated to the parameters rank and convexity number are in
\NP-complete and \W[1]-hard when parameterized by the solution size. We also
prove that to determine whether the percolation time of a graph is at least $k$
is \NP-complete, but polynomial for cacti or when $k\leq2$
The Parameterized Inapproximability Hypothesis (PIH), which is an analog of
the PCP theorem in parameterized complexity, asserts that, there is a constant
$\varepsilon> 0$ such that for any computable function
$f:\mathbb{N}\to\mathbb{N}$, no $f(k)\cdot n^{O(1)}$-time algorithm can, on
input a $k$-variable CSP instance with domain size $n$, find an assignment
satisfying $1-\varepsilon$ fraction of the constraints. A recent work by
Guruswami, Lin, Ren, Sun, and Wu (STOC'24) established PIH under the
Exponential Time Hypothesis (ETH).
In this work, we improve the quantitative aspects of PIH and prove (under
ETH) that approximating sparse parameterized CSPs within a constant factor
requires $n^{k^{1-o(1)}}$ time. This immediately implies that, assuming ETH,
finding a $(k/2)$-clique in an $n$-vertex graph with a $k$-clique requires
$n^{k^{1-o(1)}}$ time. We also prove almost optimal time lower bounds for
approximating $k$-ExactCover and Max $k$-Coverage.
Our proof follows the blueprint of the previous work to identify a
"vector-structured" ETH-hard CSP whose satisfiability can be checked via an
appropriate form of "parallel" PCP. Using further ideas in the reduction, we
guarantee additional structures for constraints in the CSP. We then leverage
this to design a parallel PCP of almost linear size based on Reed-Muller codes
and derandomized low degree testing.
The Parameterized Inapproximability Hypothesis (PIH), which is an analog of
the PCP theorem in parameterized complexity, asserts that, there is a constant
$\varepsilon> 0$ such that for any computable function
$f:\mathbb{N}\to\mathbb{N}$, no $f(k)\cdot n^{O(1)}$-time algorithm can, on
input a $k$-variable CSP instance with domain size $n$, find an assignment
satisfying $1-\varepsilon$ fraction of the constraints. A recent work by
Guruswami, Lin, Ren, Sun, and Wu (STOC'24) established PIH under the
Exponential Time Hypothesis (ETH).
In this work, we improve the quantitative aspects of PIH and prove (under
ETH) that approximating sparse parameterized CSPs within a constant factor
requires $n^{k^{1-o(1)}}$ time. This immediately implies that, assuming ETH,
finding a $(k/2)$-clique in an $n$-vertex graph with a $k$-clique requires
$n^{k^{1-o(1)}}$ time. We also prove almost optimal time lower bounds for
approximating $k$-ExactCover and Max $k$-Coverage.
Our proof follows the blueprint of the previous work to identify a
"vector-structured" ETH-hard CSP whose satisfiability can be checked via an
appropriate form of "parallel" PCP. Using further ideas in the reduction, we
guarantee additional structures for constraints in the CSP. We then leverage
this to design a parallel PCP of almost linear size based on Reed-Muller codes
and derandomized low degree testing.
Authors: William Merrill, Jackson Petty, Ashish Sabharwal
State-space models (SSMs) have emerged as a potential alternative
architecture for building large language models (LLMs) compared to the
previously ubiquitous transformer architecture. One theoretical weakness of
transformers is that they cannot express certain kinds of sequential
computation and state tracking (Merrill and Sabharwal, 2023), which SSMs are
explicitly designed to address via their close architectural similarity to
recurrent neural networks (RNNs). But do SSMs truly have an advantage (over
transformers) in expressive power for state tracking? Surprisingly, the answer
is no. Our analysis reveals that the expressive power of SSMs is limited very
similarly to transformers: SSMs cannot express computation outside the
complexity class $\mathsf{TC}^0$. In particular, this means they cannot solve
simple state-tracking problems like permutation composition. It follows that
SSMs are provably unable to accurately track chess moves with certain notation,
evaluate code, or track entities in a long narrative. To supplement our formal
analysis, we report experiments showing that Mamba-style SSMs indeed struggle
with state tracking. Thus, despite its recurrent formulation, the "state" in an
SSM is an illusion: SSMs have similar expressiveness limitations to
non-recurrent models like transformers, which may fundamentally limit their
ability to solve real-world state-tracking problems.
State-space models (SSMs) have emerged as a potential alternative
architecture for building large language models (LLMs) compared to the
previously ubiquitous transformer architecture. One theoretical weakness of
transformers is that they cannot express certain kinds of sequential
computation and state tracking (Merrill and Sabharwal, 2023), which SSMs are
explicitly designed to address via their close architectural similarity to
recurrent neural networks (RNNs). But do SSMs truly have an advantage (over
transformers) in expressive power for state tracking? Surprisingly, the answer
is no. Our analysis reveals that the expressive power of SSMs is limited very
similarly to transformers: SSMs cannot express computation outside the
complexity class $\mathsf{TC}^0$. In particular, this means they cannot solve
simple state-tracking problems like permutation composition. It follows that
SSMs are provably unable to accurately track chess moves with certain notation,
evaluate code, or track entities in a long narrative. To supplement our formal
analysis, we report experiments showing that Mamba-style SSMs indeed struggle
with state tracking. Thus, despite its recurrent formulation, the "state" in an
SSM is an illusion: SSMs have similar expressiveness limitations to
non-recurrent models like transformers, which may fundamentally limit their
ability to solve real-world state-tracking problems.
Authors: Ambroise Baril, Miguel Couceiro, Victor Lagerkvist
In this paper we are interested in the fine-grained complexity of deciding
whether there is a homomorphism from an input graph $G$ to a fixed graph $H$
(the $H$-Coloring problem). The starting point is that these problems can be
viewed as constraint satisfaction problems (CSPs), and that (partial)
polymorphisms of binary relations are of paramount importance in the study of
complexity classes of such CSPs.
Thus, we first investigate the expressivity of binary symmetric relations
$E_H$ and their corresponding (partial) polymorphisms pPol($E_H$). For
irreflexive graphs we observe that there is no pair of graphs $H$ and $H'$ such
that pPol($E_H$) $\subseteq$ pPol($E_{H'}$), unless $E_{H'}= \emptyset$ or $H
=H'$. More generally we show the existence of an $n$-ary relation $R$ whose
partial polymorphisms strictly subsume those of $H$ and such that CSP($R$) is
NP-complete if and only if $H$ contains an odd cycle of length at most $n$.
Motivated by this we also describe the sets of total polymorphisms of
nontrivial cliques, odd cycles, as well as certain cores, and we give an
algebraic characterization of projective cores. As a by-product, we settle the
Okrasa and Rz\k{a}\.zewski conjecture for all graphs of at most 7 vertices.
In this paper we are interested in the fine-grained complexity of deciding
whether there is a homomorphism from an input graph $G$ to a fixed graph $H$
(the $H$-Coloring problem). The starting point is that these problems can be
viewed as constraint satisfaction problems (CSPs), and that (partial)
polymorphisms of binary relations are of paramount importance in the study of
complexity classes of such CSPs.
Thus, we first investigate the expressivity of binary symmetric relations
$E_H$ and their corresponding (partial) polymorphisms pPol($E_H$). For
irreflexive graphs we observe that there is no pair of graphs $H$ and $H'$ such
that pPol($E_H$) $\subseteq$ pPol($E_{H'}$), unless $E_{H'}= \emptyset$ or $H
=H'$. More generally we show the existence of an $n$-ary relation $R$ whose
partial polymorphisms strictly subsume those of $H$ and such that CSP($R$) is
NP-complete if and only if $H$ contains an odd cycle of length at most $n$.
Motivated by this we also describe the sets of total polymorphisms of
nontrivial cliques, odd cycles, as well as certain cores, and we give an
algebraic characterization of projective cores. As a by-product, we settle the
Okrasa and Rz\k{a}\.zewski conjecture for all graphs of at most 7 vertices.
Authors: Diana Marin, Filippo Maggioli, Simone Melzi, Stefan Ohrhallinger, Michael Wimmer
Reconstructing 2D curves from sample points has long been a critical
challenge in computer graphics, finding essential applications in vector
graphics. The design and editing of curves on surfaces has only recently begun
to receive attention, primarily relying on human assistance, and where not,
limited by very strict sampling conditions. In this work, we formally improve
on the state-of-the-art requirements and introduce an innovative algorithm
capable of reconstructing closed curves directly on surfaces from a given
sparse set of sample points. We extend and adapt a state-of-the-art planar
curve reconstruction method to the realm of surfaces while dealing with the
challenges arising from working on non-Euclidean domains. We demonstrate the
robustness of our method by reconstructing multiple curves on various surface
meshes. We explore novel potential applications of our approach, allowing for
automated reconstruction of curves on Riemannian manifolds.
Reconstructing 2D curves from sample points has long been a critical
challenge in computer graphics, finding essential applications in vector
graphics. The design and editing of curves on surfaces has only recently begun
to receive attention, primarily relying on human assistance, and where not,
limited by very strict sampling conditions. In this work, we formally improve
on the state-of-the-art requirements and introduce an innovative algorithm
capable of reconstructing closed curves directly on surfaces from a given
sparse set of sample points. We extend and adapt a state-of-the-art planar
curve reconstruction method to the realm of surfaces while dealing with the
challenges arising from working on non-Euclidean domains. We demonstrate the
robustness of our method by reconstructing multiple curves on various surface
meshes. We explore novel potential applications of our approach, allowing for
automated reconstruction of curves on Riemannian manifolds.
Authors: Doron Haviv, Russell Zhang Kunes, Thomas Dougherty, Cassandra Burdziak, Tal Nawy, Anna Gilbert, Dana Pe'er
Optimal transport (OT) and the related Wasserstein metric (W) are powerful
and ubiquitous tools for comparing distributions. However, computing pairwise
Wasserstein distances rapidly becomes intractable as cohort size grows. An
attractive alternative would be to find an embedding space in which pairwise
Euclidean distances map to OT distances, akin to standard multidimensional
scaling (MDS). We present Wasserstein Wormhole, a transformer-based autoencoder
that embeds empirical distributions into a latent space wherein Euclidean
distances approximate OT distances. Extending MDS theory, we show that our
objective function implies a bound on the error incurred when embedding
non-Euclidean distances. Empirically, distances between Wormhole embeddings
closely match Wasserstein distances, enabling linear time computation of OT
distances. Along with an encoder that maps distributions to embeddings,
Wasserstein Wormhole includes a decoder that maps embeddings back to
distributions, allowing for operations in the embedding space to generalize to
OT spaces, such as Wasserstein barycenter estimation and OT interpolation. By
lending scalability and interpretability to OT approaches, Wasserstein Wormhole
unlocks new avenues for data analysis in the fields of computational geometry
and single-cell biology.
Optimal transport (OT) and the related Wasserstein metric (W) are powerful
and ubiquitous tools for comparing distributions. However, computing pairwise
Wasserstein distances rapidly becomes intractable as cohort size grows. An
attractive alternative would be to find an embedding space in which pairwise
Euclidean distances map to OT distances, akin to standard multidimensional
scaling (MDS). We present Wasserstein Wormhole, a transformer-based autoencoder
that embeds empirical distributions into a latent space wherein Euclidean
distances approximate OT distances. Extending MDS theory, we show that our
objective function implies a bound on the error incurred when embedding
non-Euclidean distances. Empirically, distances between Wormhole embeddings
closely match Wasserstein distances, enabling linear time computation of OT
distances. Along with an encoder that maps distributions to embeddings,
Wasserstein Wormhole includes a decoder that maps embeddings back to
distributions, allowing for operations in the embedding space to generalize to
OT spaces, such as Wasserstein barycenter estimation and OT interpolation. By
lending scalability and interpretability to OT approaches, Wasserstein Wormhole
unlocks new avenues for data analysis in the fields of computational geometry
and single-cell biology.
Computing distances on Riemannian manifolds is a challenging problem with
numerous applications, from physics, through statistics, to machine learning.
In this paper, we introduce the metric-constrained Eikonal solver to obtain
continuous, differentiable representations of distance functions on manifolds.
The differentiable nature of these representations allows for the direct
computation of globally length-minimising paths on the manifold. We showcase
the use of metric-constrained Eikonal solvers for a range of manifolds and
demonstrate the applications. First, we demonstrate that metric-constrained
Eikonal solvers can be used to obtain the Fr\'echet mean on a manifold,
employing the definition of a Gaussian mixture model, which has an analytical
solution to verify the numerical results. Second, we demonstrate how the
obtained distance function can be used to conduct unsupervised clustering on
the manifold -- a task for which existing approaches are computationally
prohibitive. This work opens opportunities for distance computations on
manifolds.
Computing distances on Riemannian manifolds is a challenging problem with
numerous applications, from physics, through statistics, to machine learning.
In this paper, we introduce the metric-constrained Eikonal solver to obtain
continuous, differentiable representations of distance functions on manifolds.
The differentiable nature of these representations allows for the direct
computation of globally length-minimising paths on the manifold. We showcase
the use of metric-constrained Eikonal solvers for a range of manifolds and
demonstrate the applications. First, we demonstrate that metric-constrained
Eikonal solvers can be used to obtain the Fr\'echet mean on a manifold,
employing the definition of a Gaussian mixture model, which has an analytical
solution to verify the numerical results. Second, we demonstrate how the
obtained distance function can be used to conduct unsupervised clustering on
the manifold -- a task for which existing approaches are computationally
prohibitive. This work opens opportunities for distance computations on
manifolds.